Introduction to System Design
System Design is the process of defining the architecture, components, modules, interfaces, and data for a system to fulfill specific business requirements, while ensuring scalability, maintainability, and performance.SHOW CONTENTS
Load Balancing
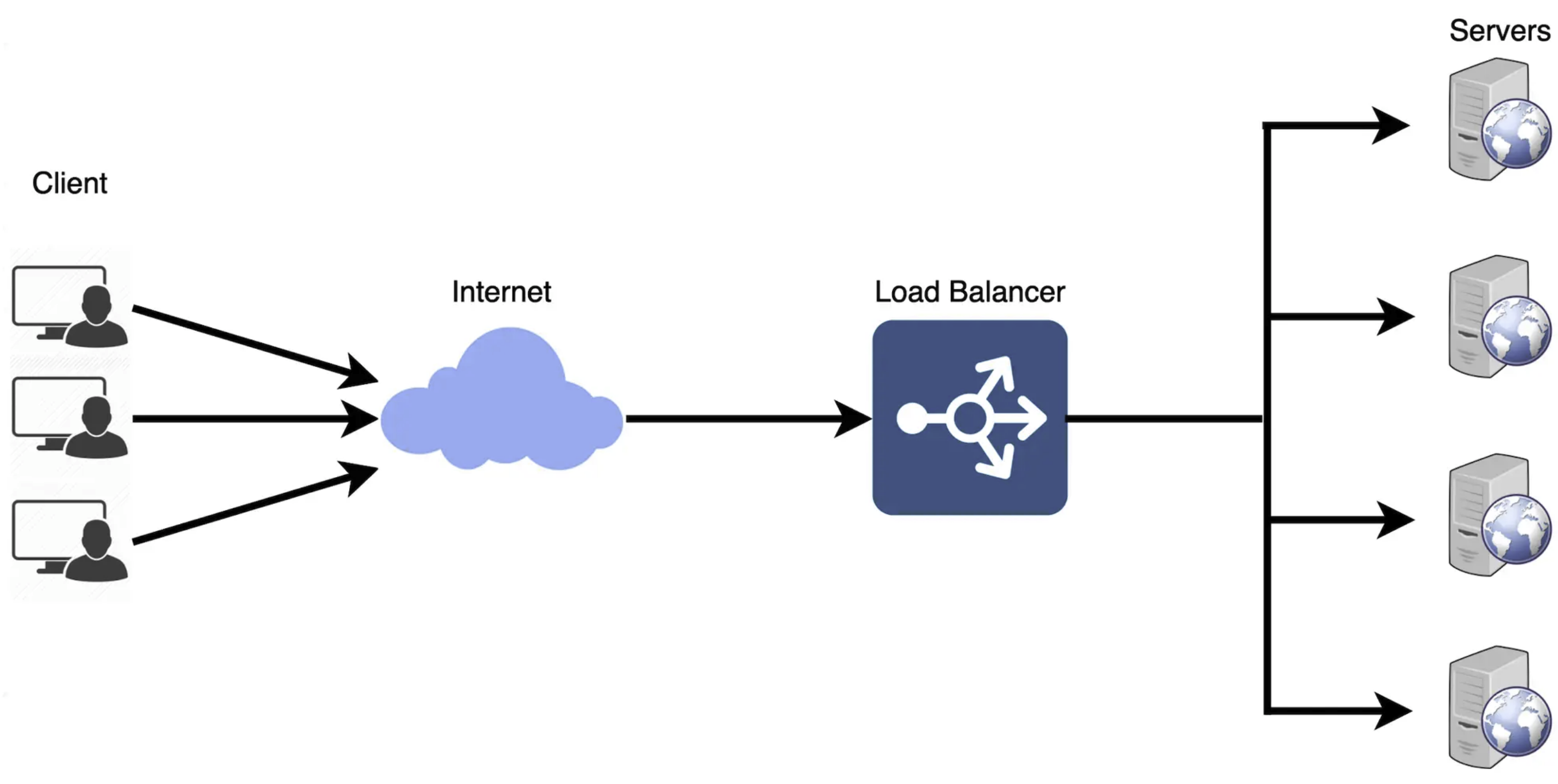
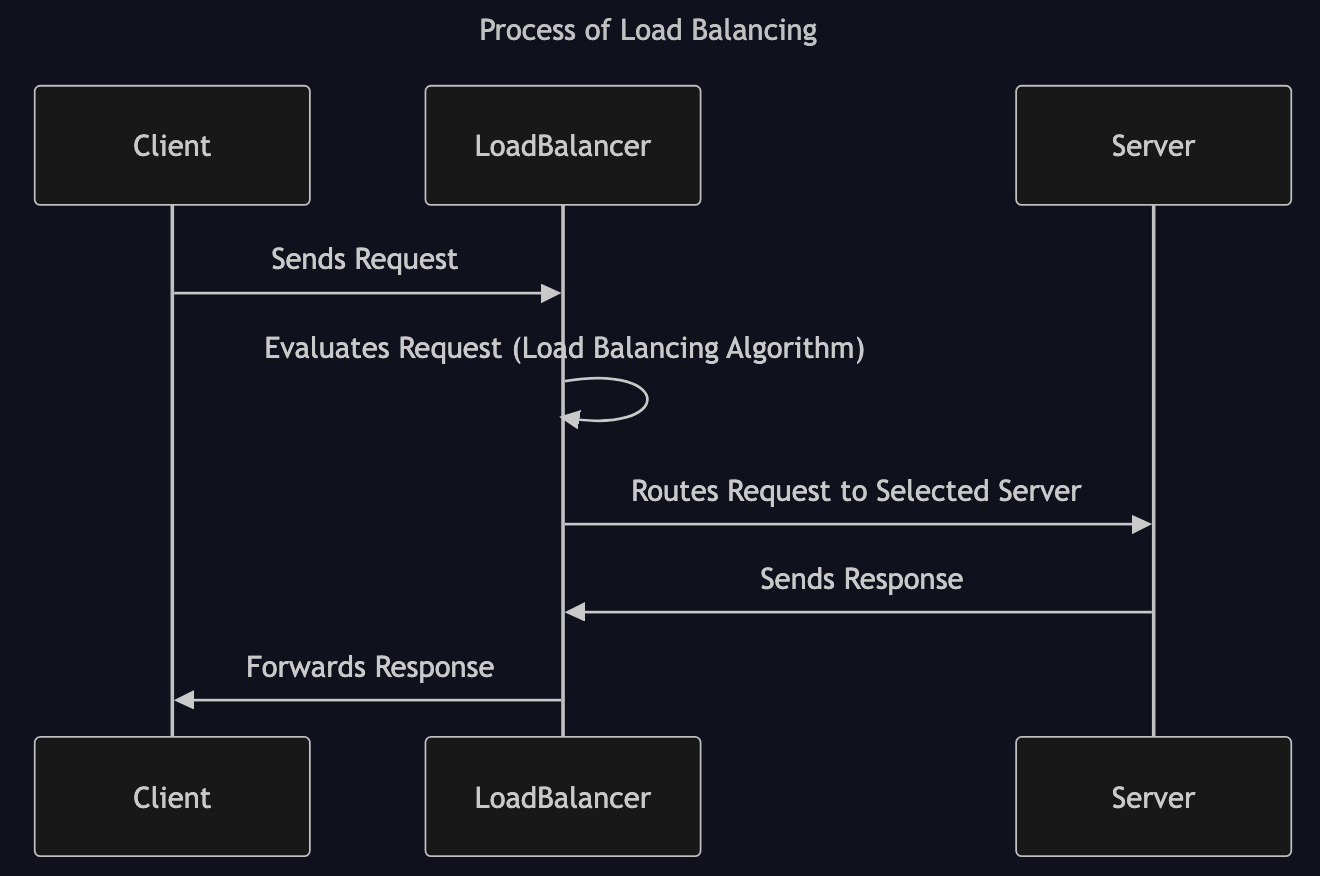
In System Design, Load Balancing refers to the practice of distributing incoming network traffic or workload across multiple servers or resources to optimize resource use and ensure high availability. To fullly leverage scalability and redundency, load balancing can occur at different layers: between user and the web server, between web server and an internal platform serve, between internal platform server and database as illustrated in the following image: The typical process of load balancing involves the following steps:SHOW CONTENTS

Load Balancing Algorithms
A load balancing algorithm is a method used by a load balancer to determine how an incoming request should be distributed across multiple servers. Commonly used load balancing algorithms include Round Robin, Least Connections, Weight Round Robin, Weighted Least Connections, IP Hash, Least Response Time, Random, and Least Bandwidth.SHOW CONTENTS
Round Robin
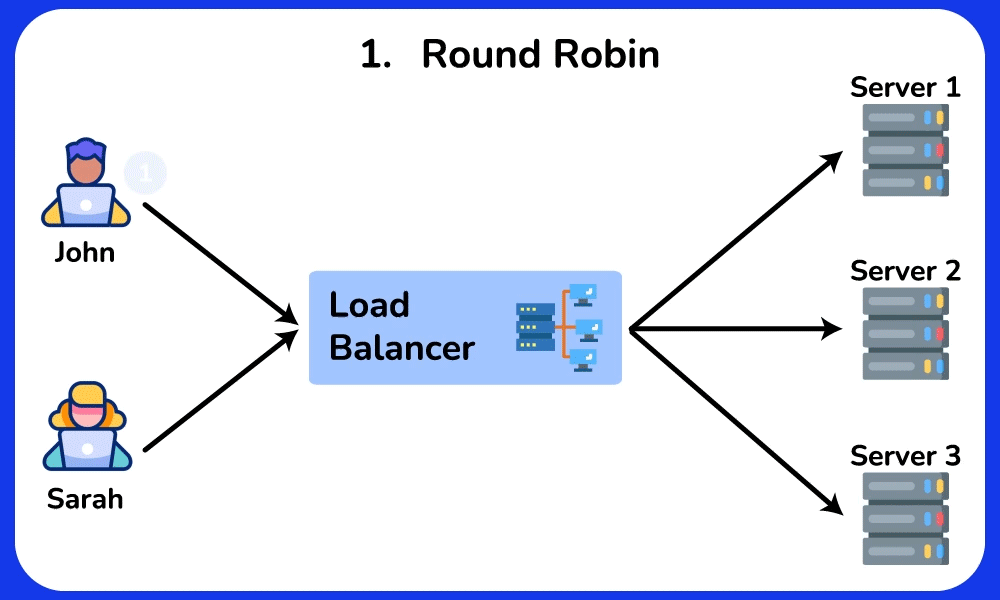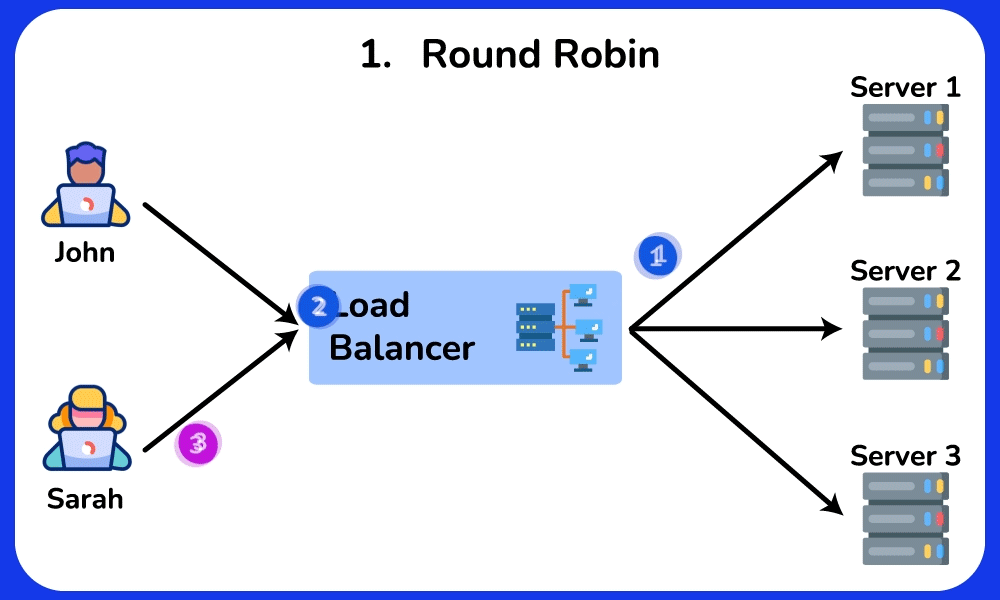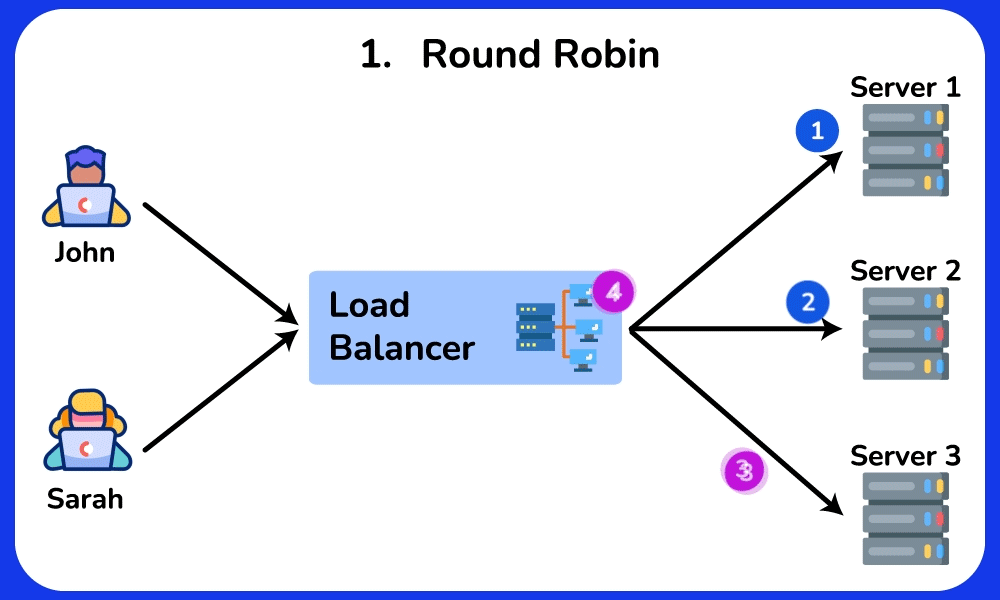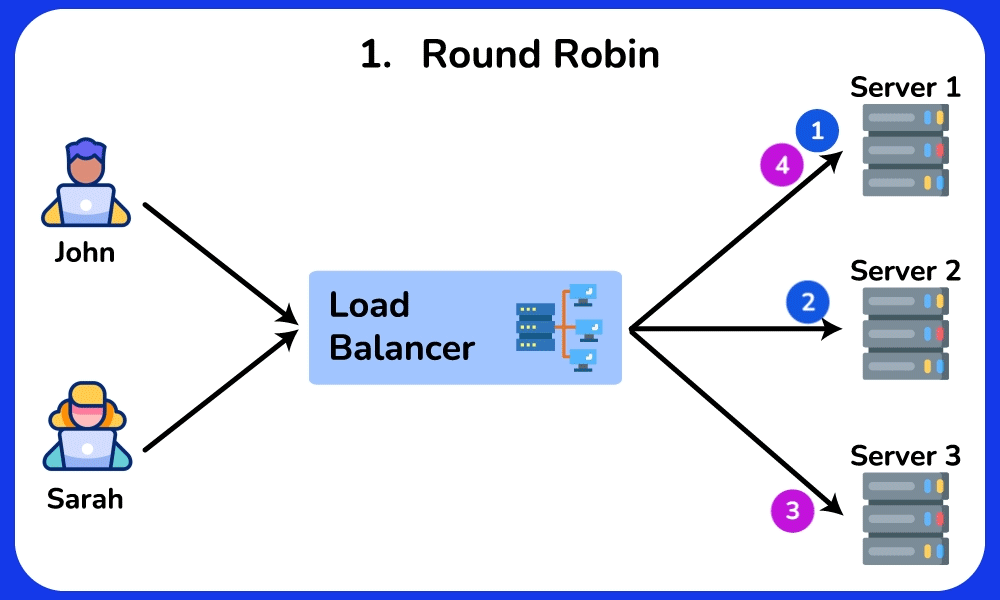
The Round Robin algorithm distributes requests evenly across multiple servers in a circular manner. This algorithm does not consider the current load or capabilities of each server. It is commonly used in environments where servers have similar capacity and performance, or in applications where each request can be handled independently.SHOW CONTENTS
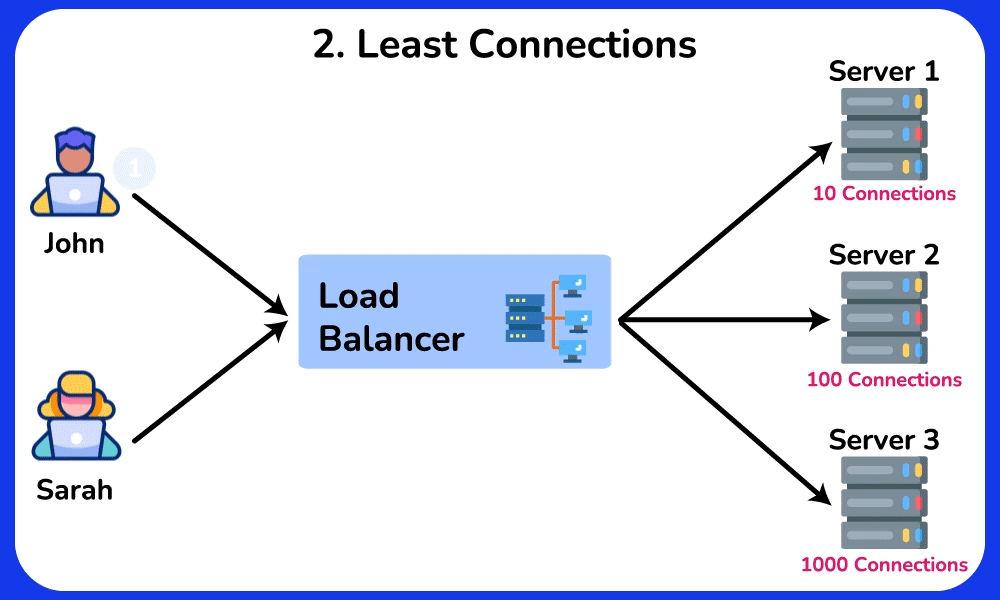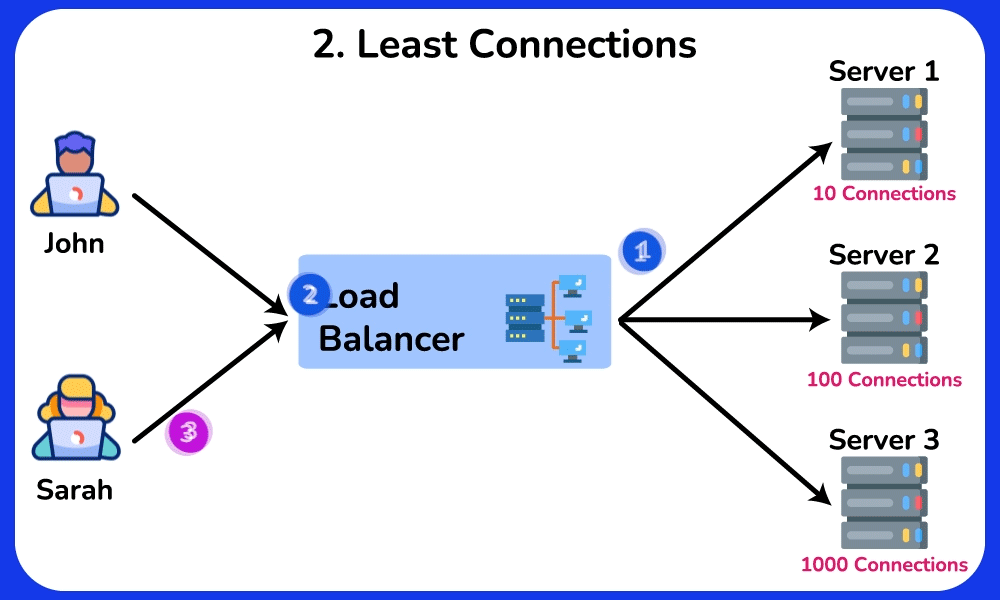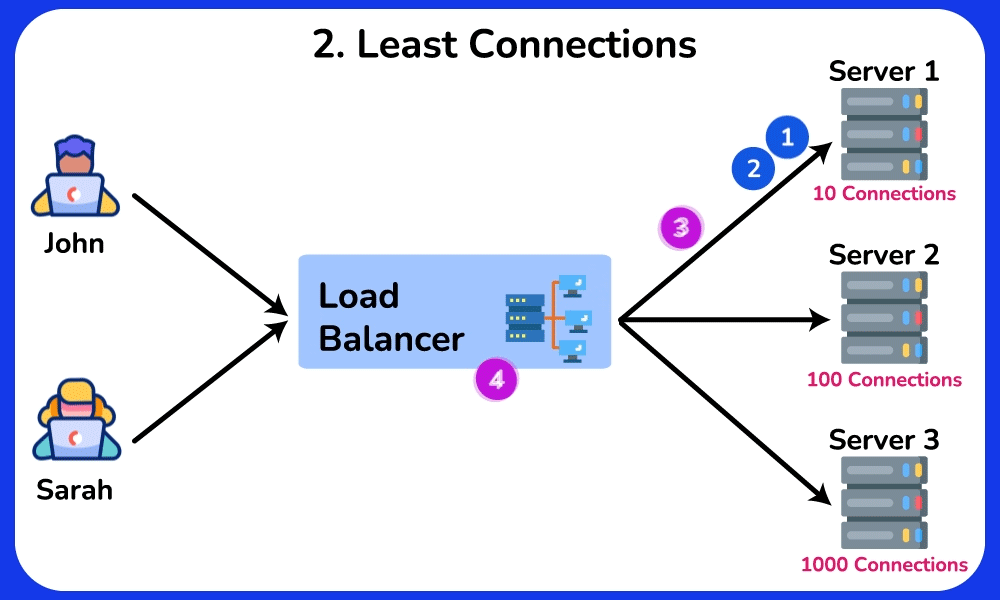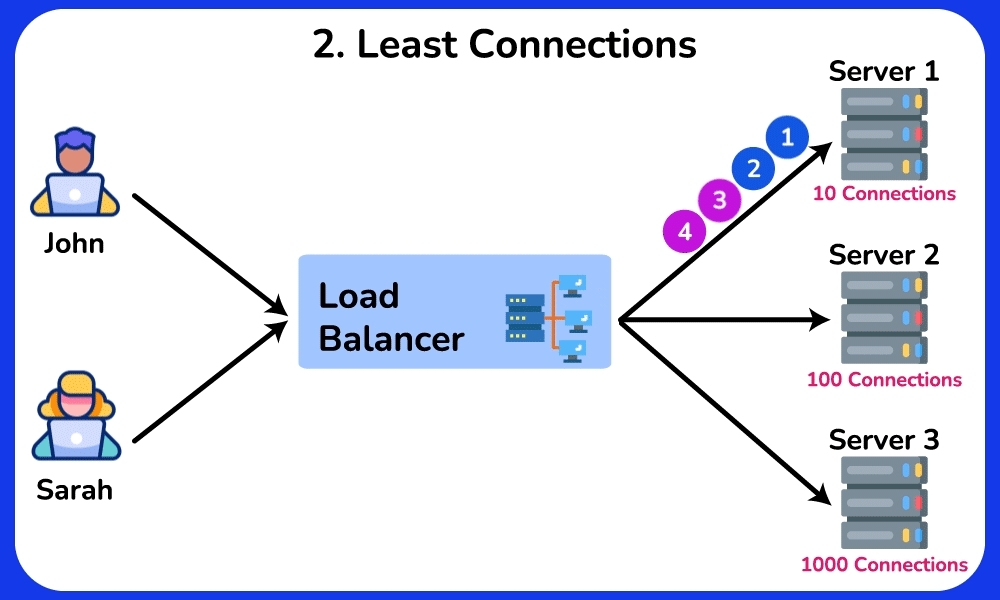
Least Connections
The Least Connections algorithm distributes requests to servers with the fewest active connections. It takes into account the server’s current workload, helping to prevent any single server from becoming overwhelmed. This algorithm is particularly useful in scenerios where traffic or workload is unpredictable, servers have varying capabilities, or maintaining session state is important.SHOW CONTENTS
Weighted Round Robin
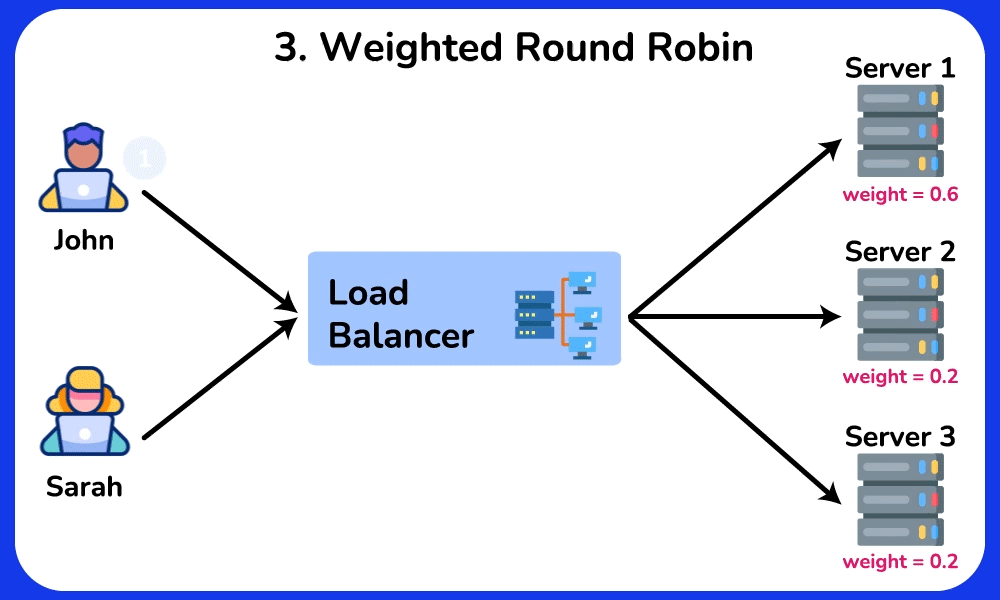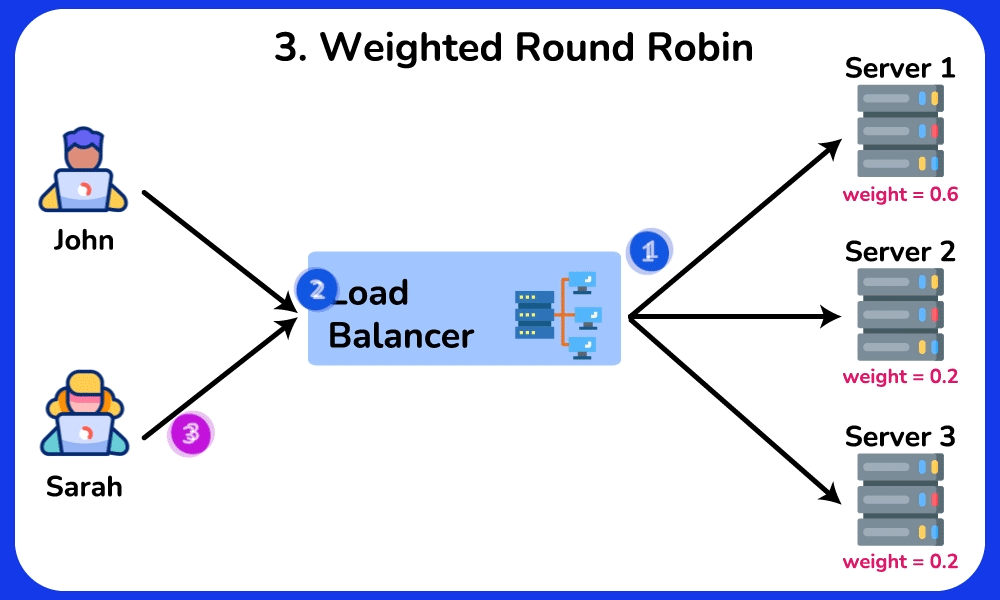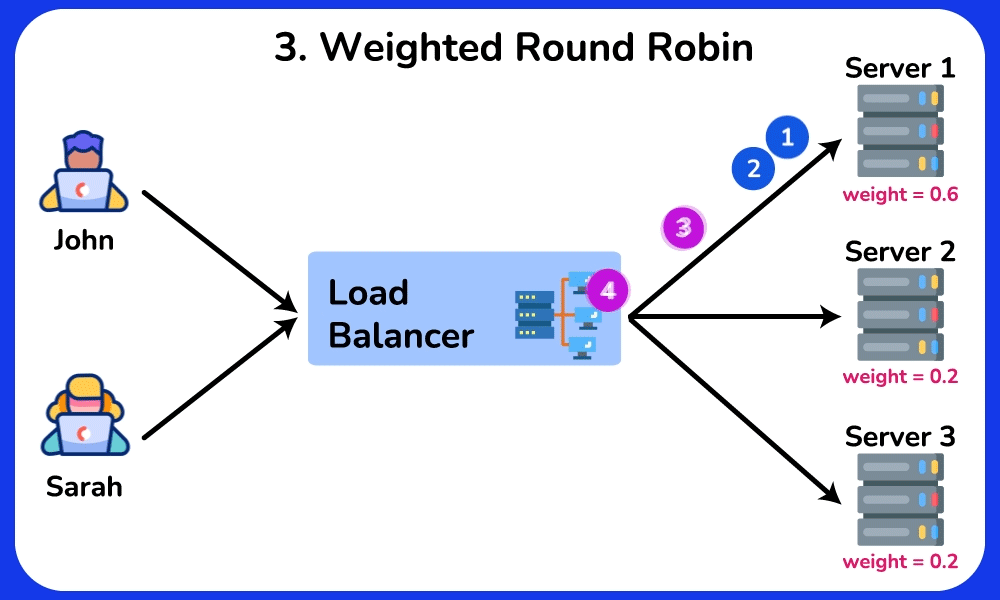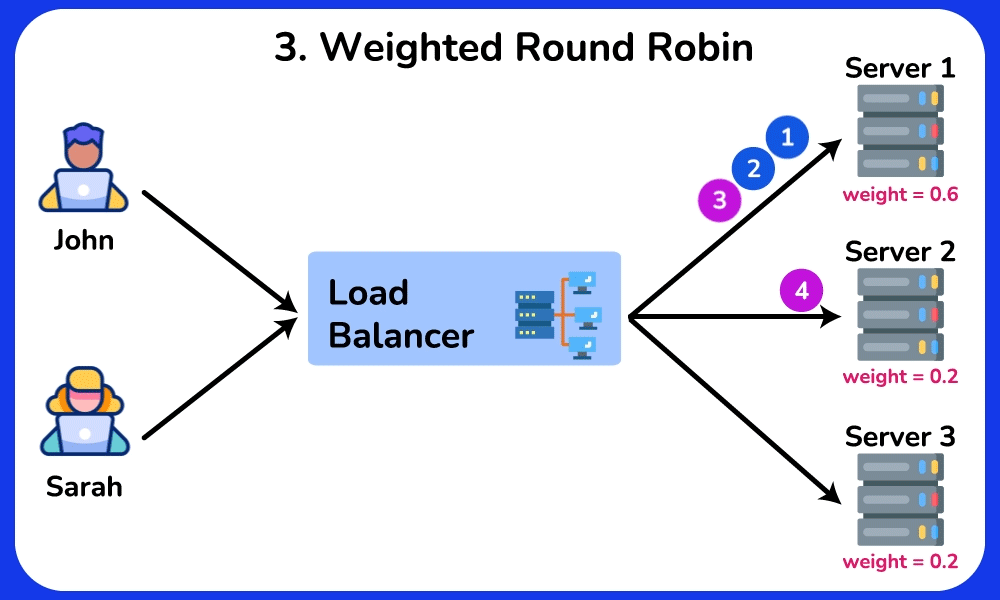
The Weighted Round Robin algorithm is an enhanced version of Round Robin, where each server is assigned a weight based on its capability and workload. Servers with higher weights process more requests, helping to prevent overloading less powerful servers. This algorithm is ideal for scenarios where servers have varying processing abilities, such as in a database cluster, where nodes with higher processing power can handle more queries.SHOW CONTENTS
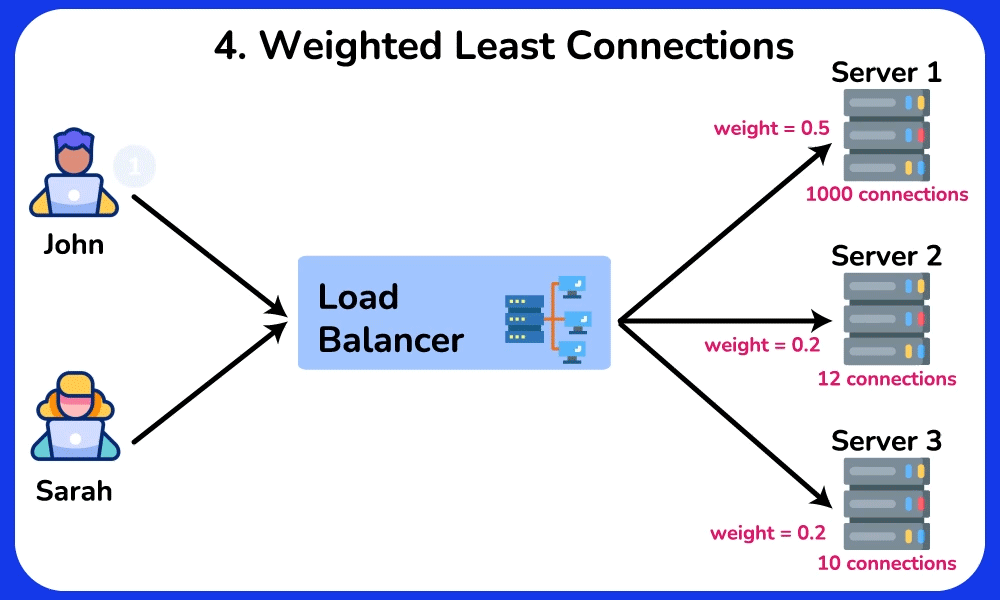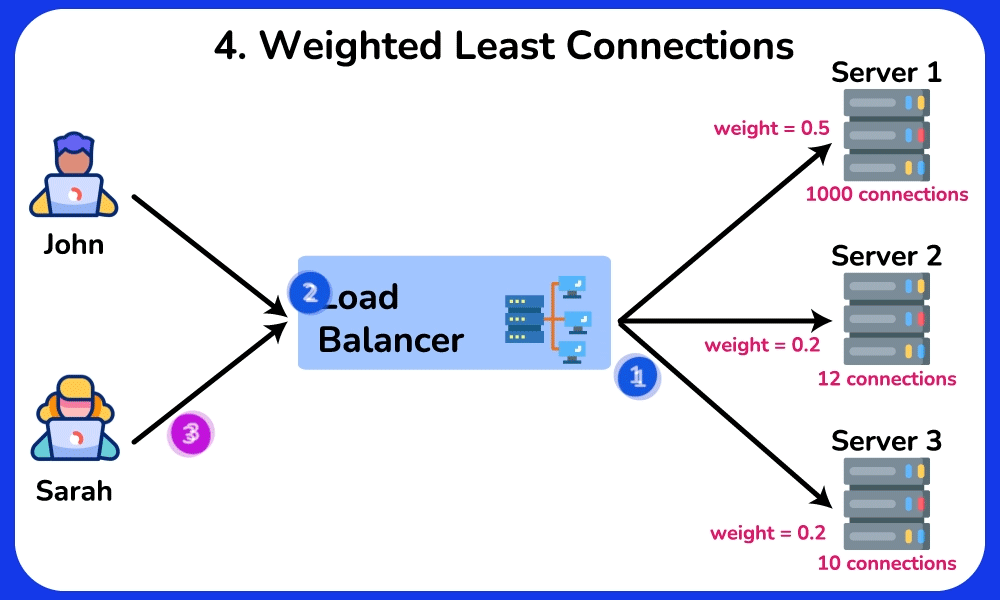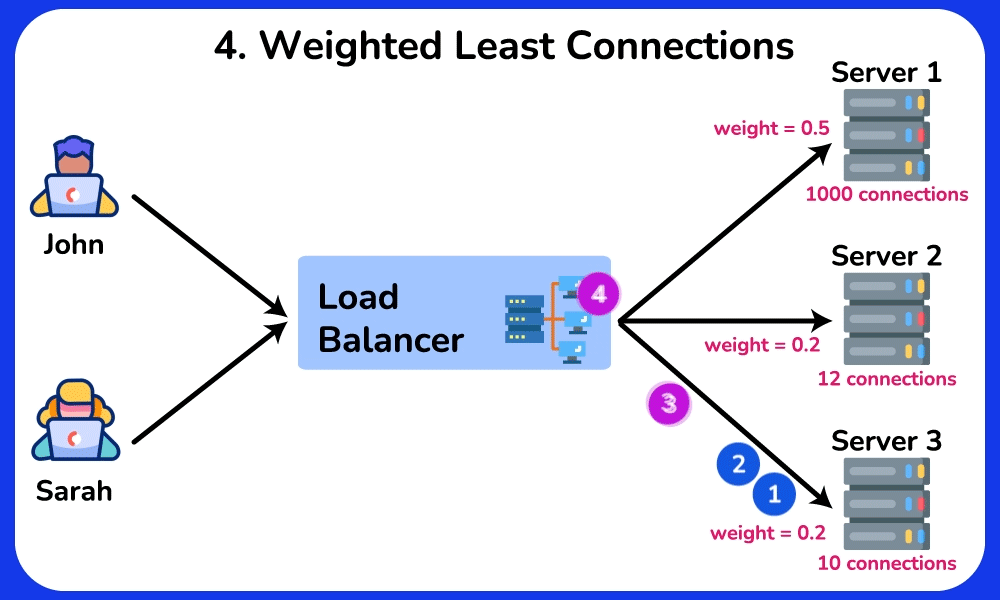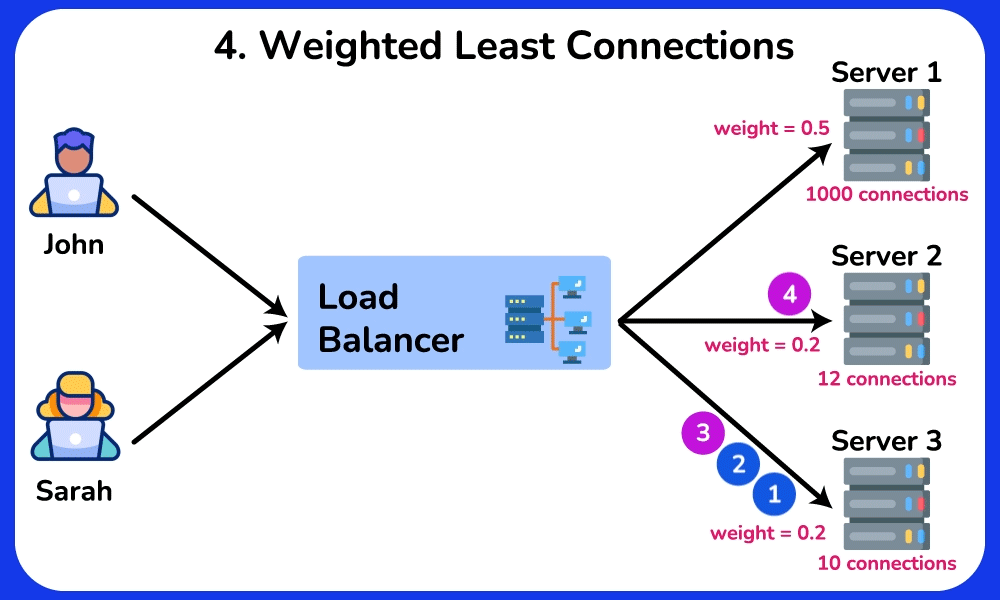
Weighted Least Connections
The Weighted Least Connections algorithm is a combination of the Least Connections and the Weighted Round Robin algorithms. It takes into account the number of active connections of each server and the weight assigned to a server based on its capability. Requests are routed to servers based on the load factor, which is commonly calculated using the formular: the number of active connections of a server divided by its weight. $$
\text{Load Factor} = \frac{\text{Number of Active Connections}}{\text{Weight of the Server}}
$$SHOW CONTENTS
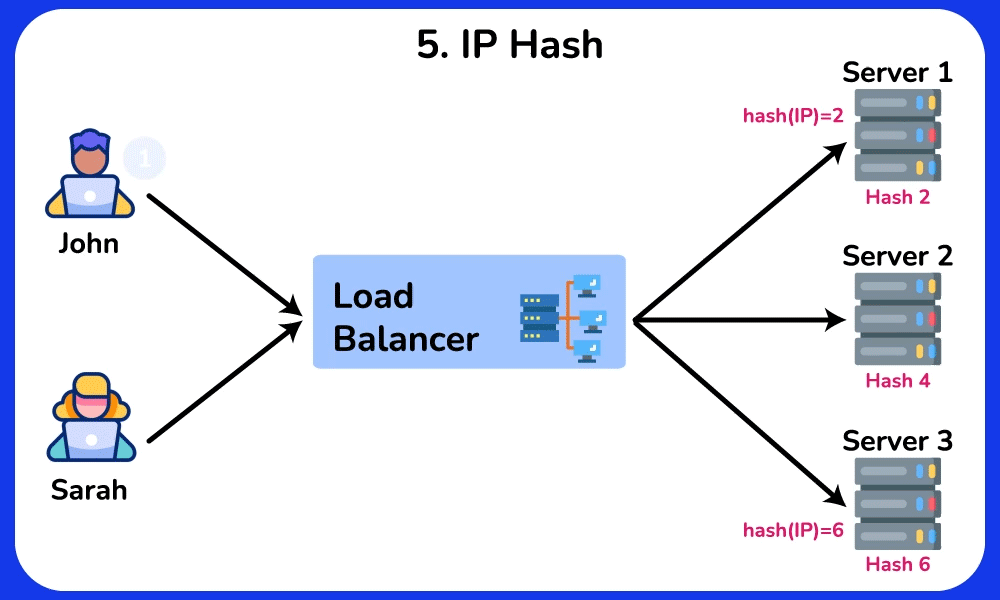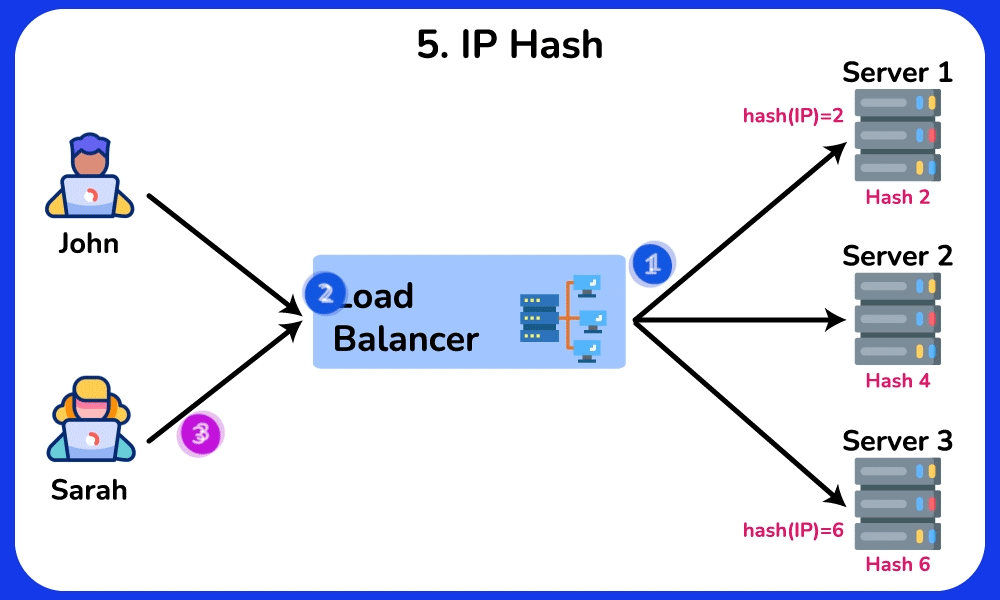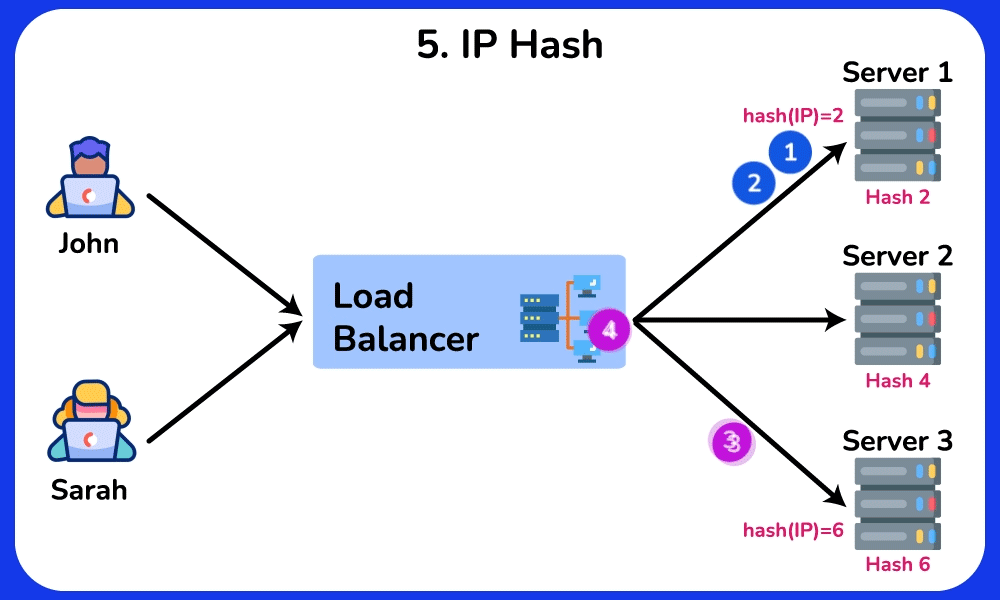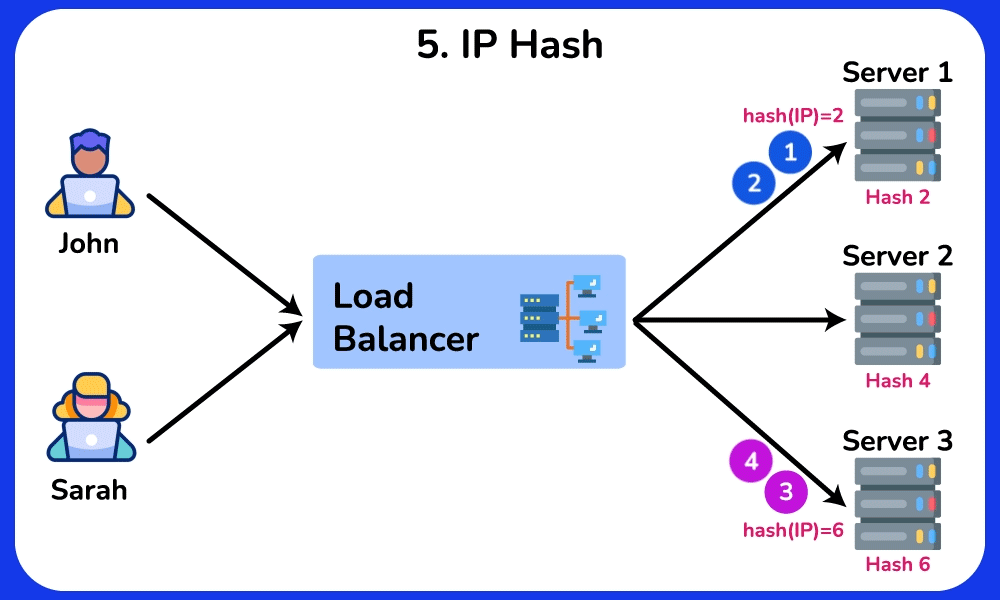
IP Hash
The IP Hash algorithm routes requests to servers based on a hash of the client’s IP address. The load balancer applies a hash function to the client’s IP address to calculate the hash value, which is then used to determined which server will handle the current request. If the distribution of client IP addresses is uneven, some servers may receive more requests than others, leading to an imbalanced load. This algorithm is ideal for scenarios where maintaining state is important, such as online shopping carts or user sessions.SHOW CONTENTS
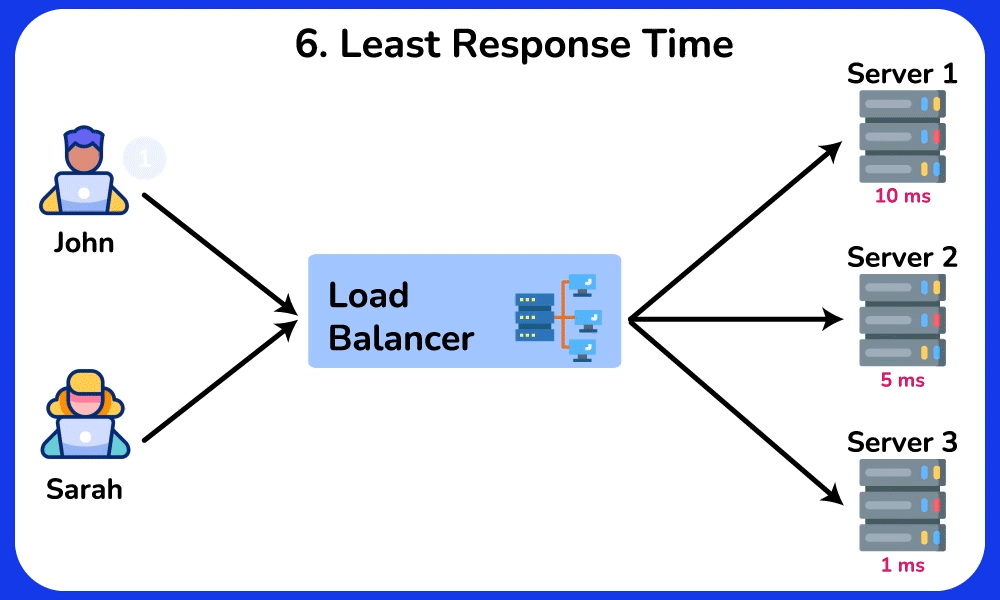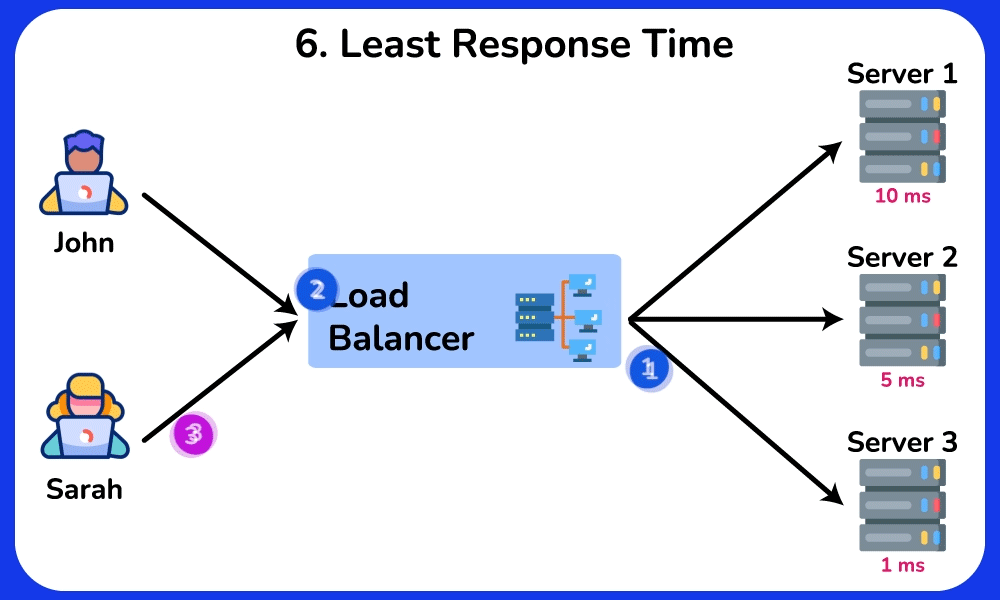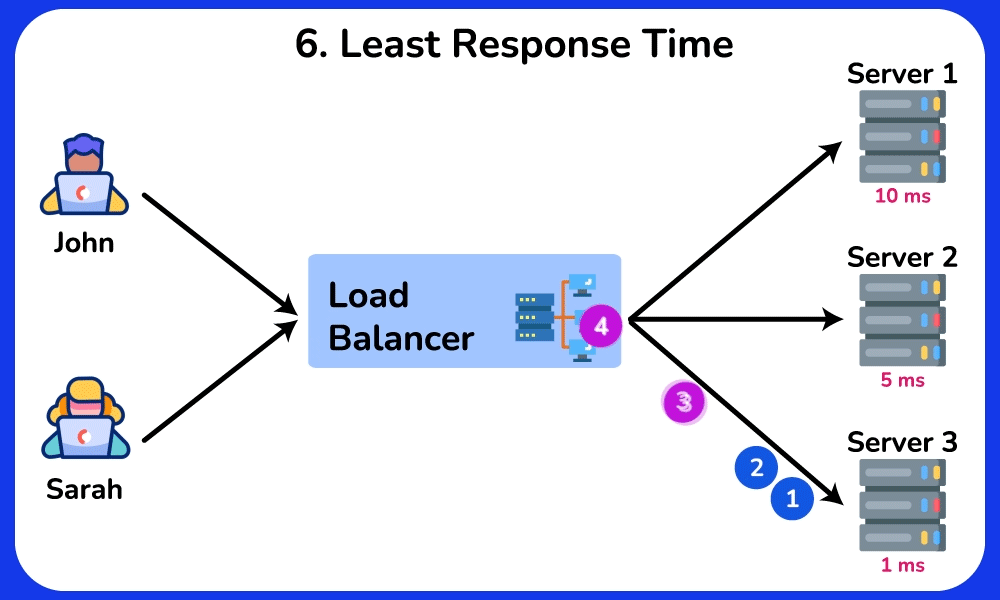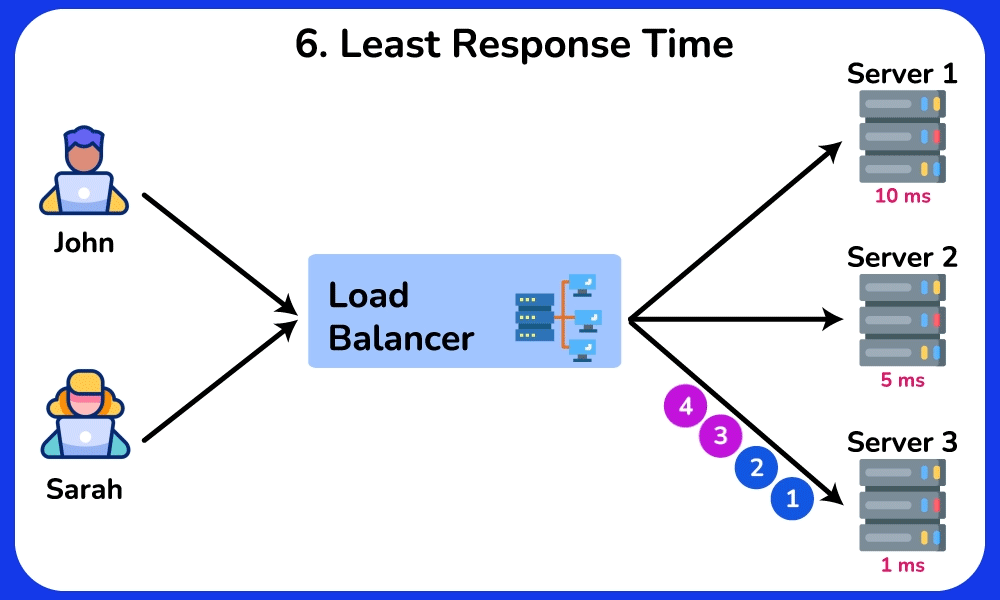
Least Response Time
The Least Response Time algorithm routes incoming requests to the server with the lowest response time, ensuring efficient resource utilization and optimal client experience. It is ideal for scenerios where low latancy and fast response times are crucial, such as online gaming and financial trading.SHOW CONTENTS
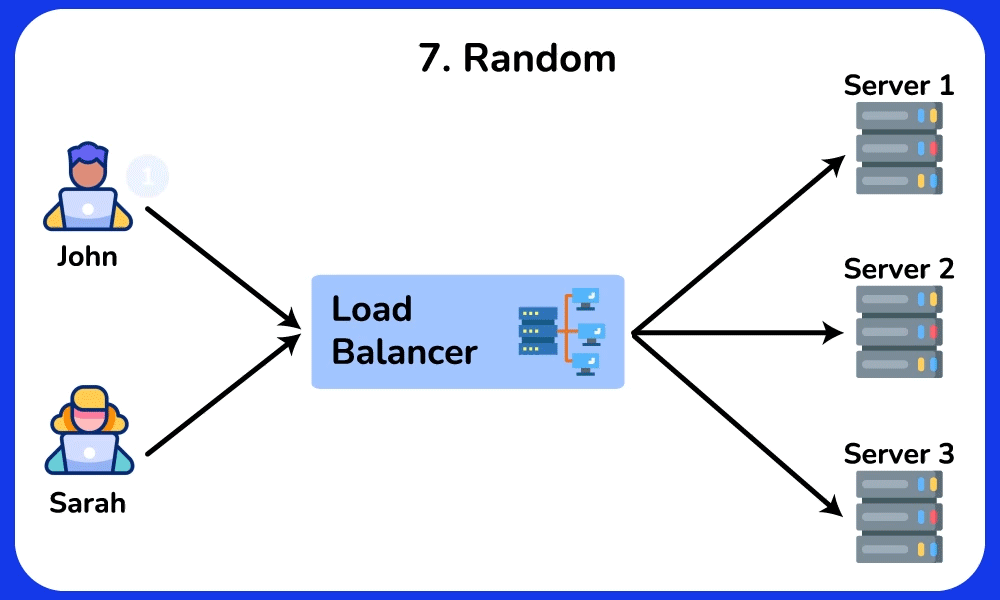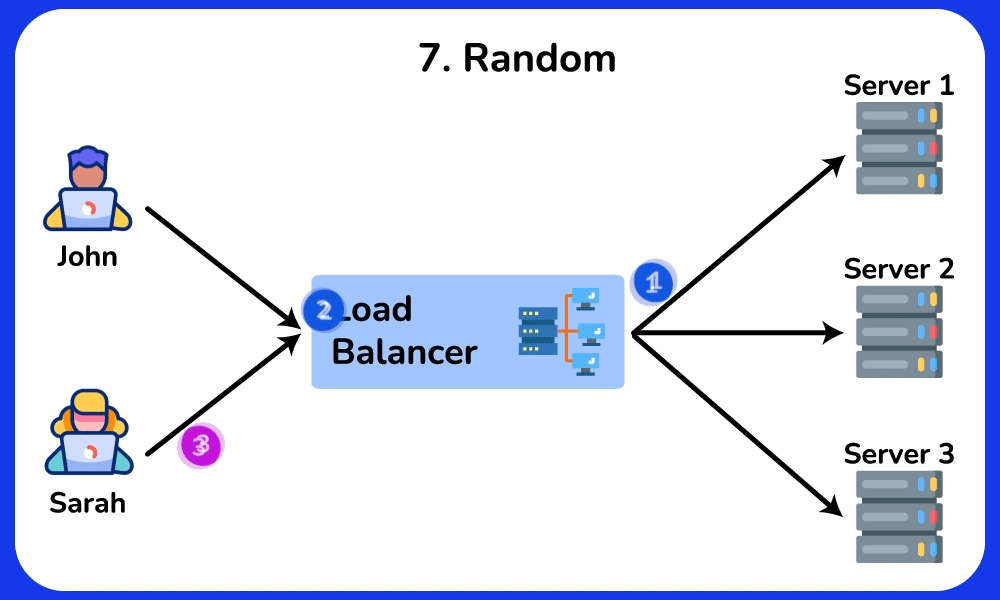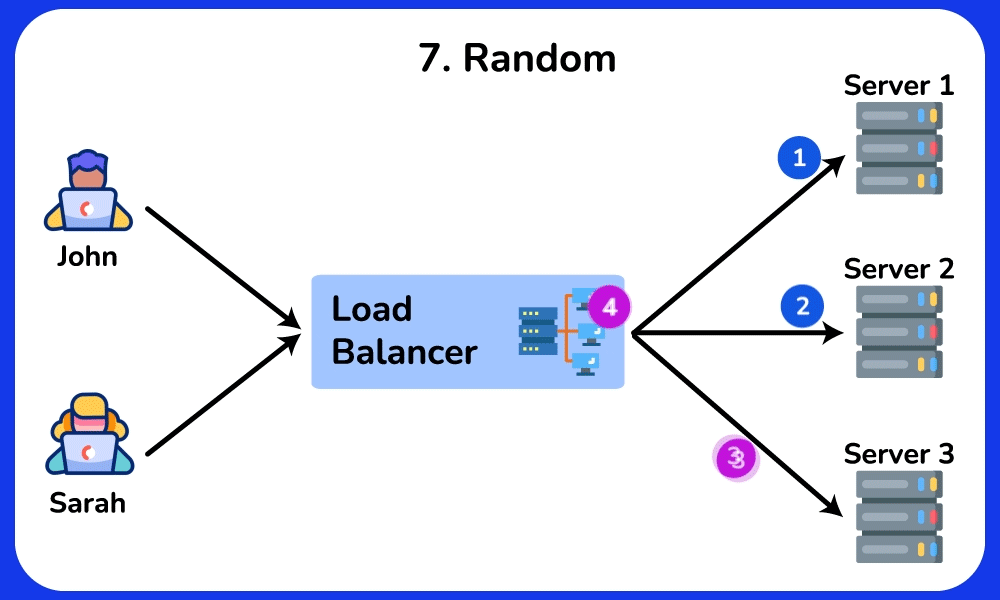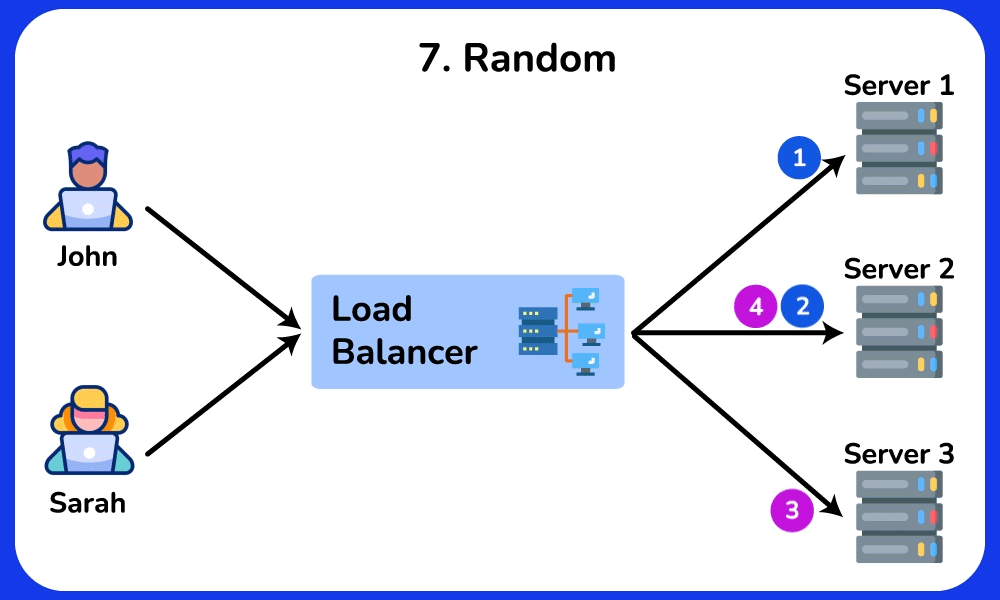
Random
The Random load balancing algorithm routes incoming requests to servers randomly. It is commonly used in scenarios where the load is relatively uniform and the servers have similar capabilities.SHOW CONTENTS
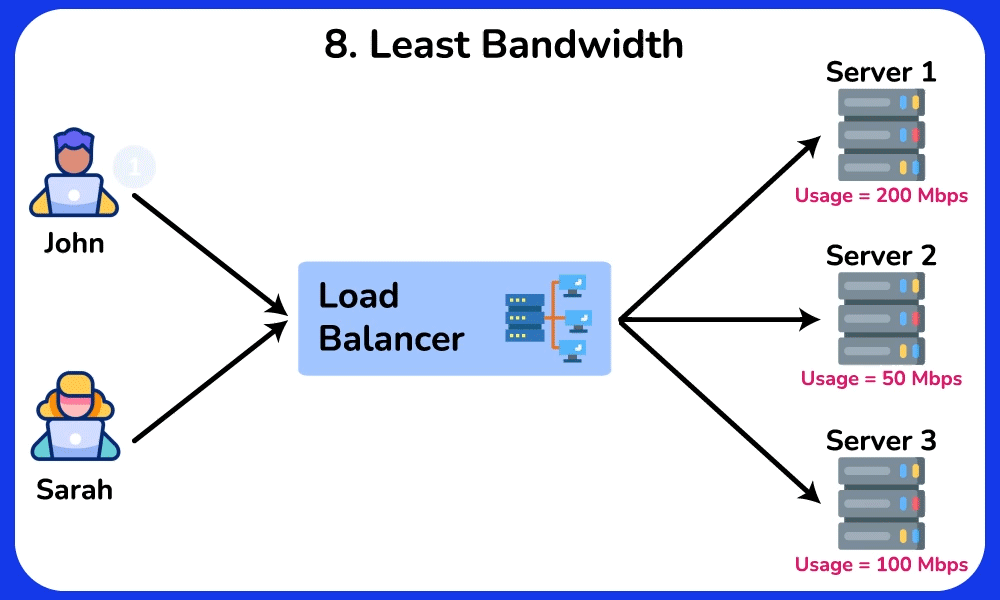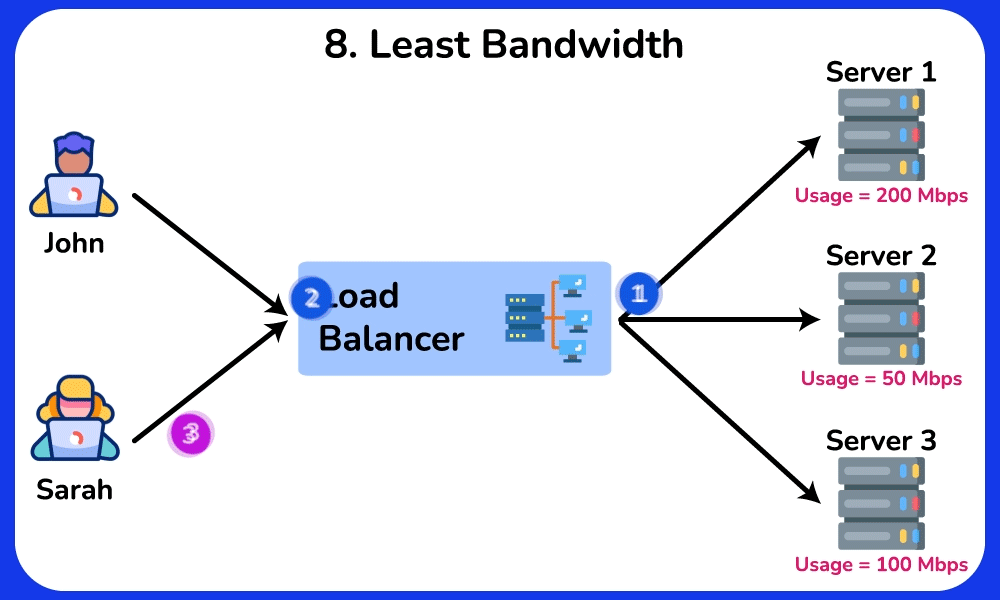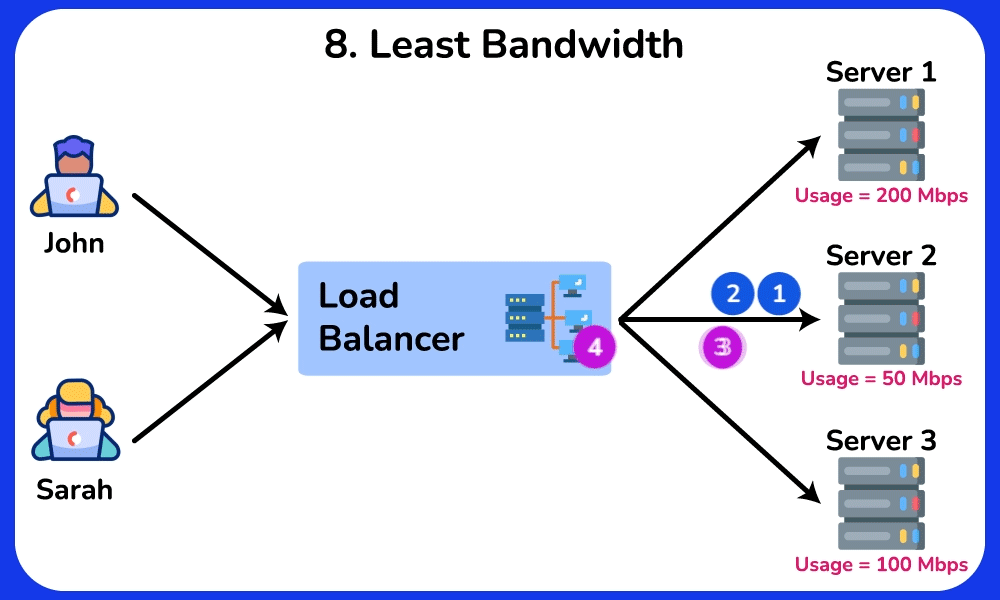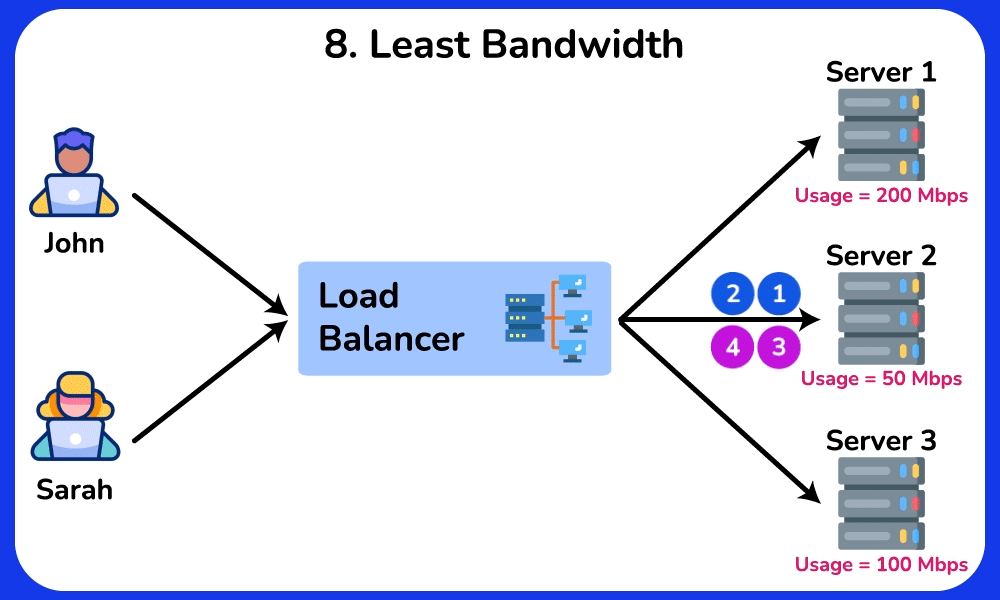
Least Bandwidth
The Least Bandwidth algorithm routes incoming requests to the server that is consuming the least amount of bandwidth. It is ideal for applications with high bandwidth usage, such as vedio streaming, file downloads, and large file transfers.SHOW CONTENTS
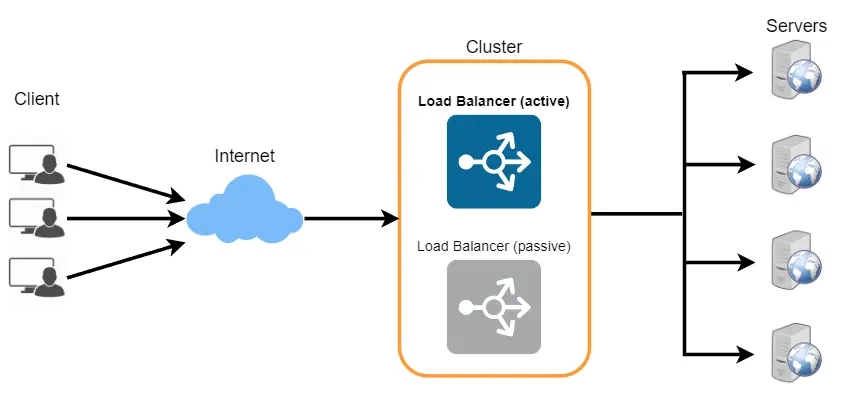
Redundent Load Balancers
The Single Point of Failure (SPOF) refers to any component in a system or infrastructure that, if it fails, causes the entire system or a significant portion of it to become unavailable. For instance, if a load balancer is responsible for routing all incoming requests to servers, its faulure would result in the entire system or application becoming inoperable. To mitigate this risk, redundent load balancers can be deployed. For example, in an active-passive setup, two load balancers are used, where both are capable of routing traffic and detecting failures. The active load balancer handles all incoming requests, and if it fails, the passive load balancer takes over to ditribute requests, ensuring continuous availability. This approach helps prevent the system from being dependent on a single point of failure, as illustrated in the following diagram.SHOW CONTENTS
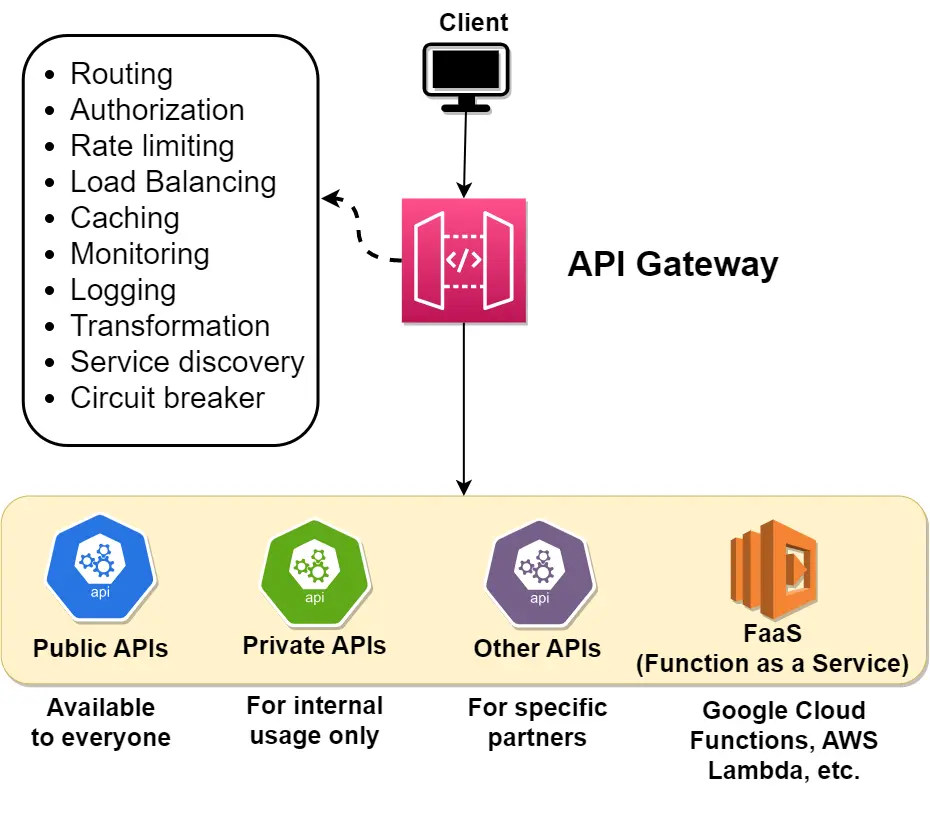
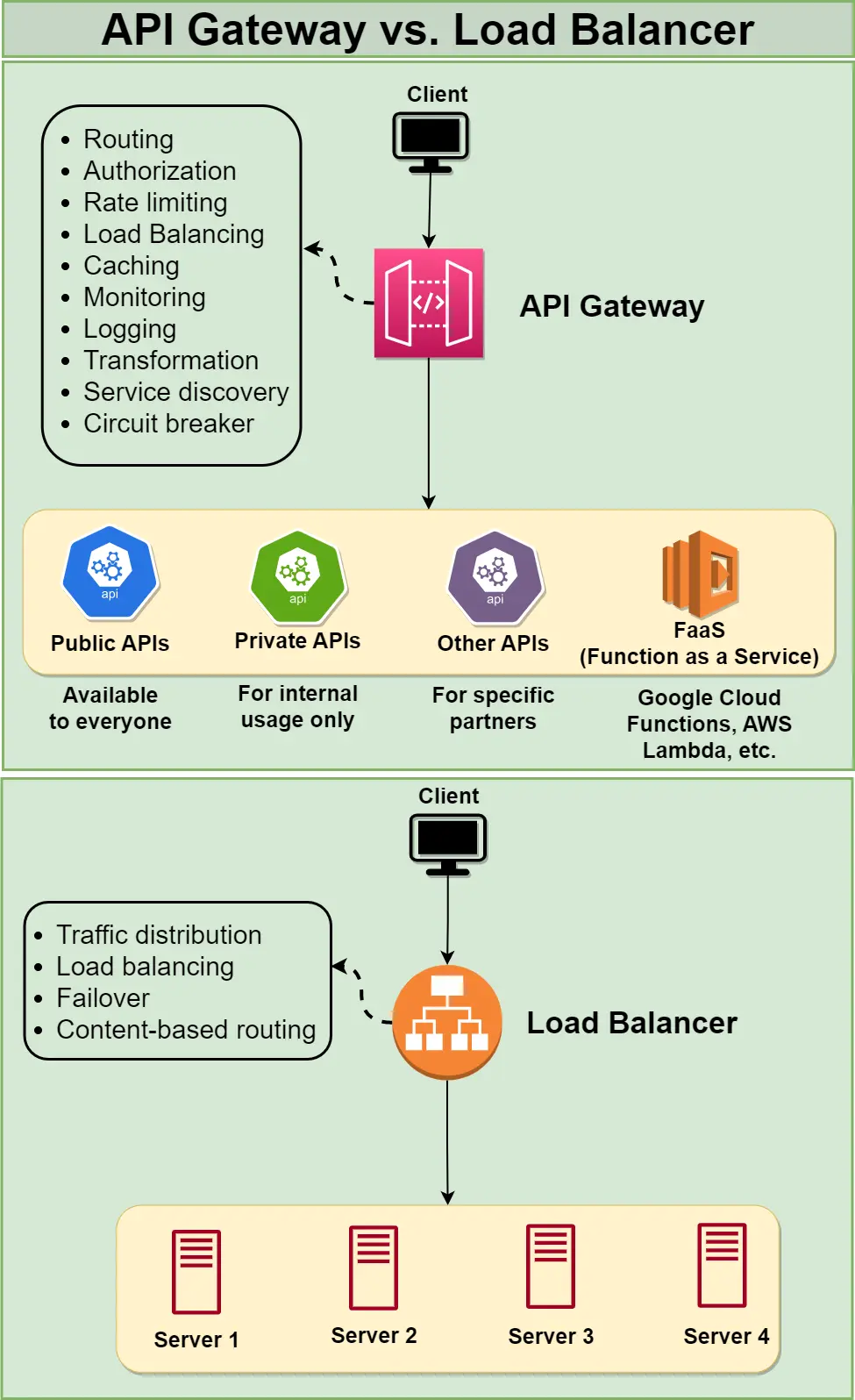
API Gateway
An API Gateway is a server-side component that acts as a central entry point for clients to access as a collection of microservices. It receives client requests, forwards them to the appropriate microservice, and then returns the response from the server to the client. The API Gateway is responsible for various tasks, such as request routing, authentication, rate limiting. The key difference between an API Gateway and a load balancer lies in their core functions. An API Gateway focuses on routing requests to specific microservices. In contrast, a Load Balancer is responsible for distributing incoming traffic across multiple backend servers. Additionally, while an API Gateway typically deals with requests that target specific APIs identified by unique URLs, a load balancer generally handles requests directed to a single, well-known IP address, distributing those requests to one of serveral backend servers based on load-balancing algorithms.SHOW CONTENTS
Key Characteristics of Distributed System
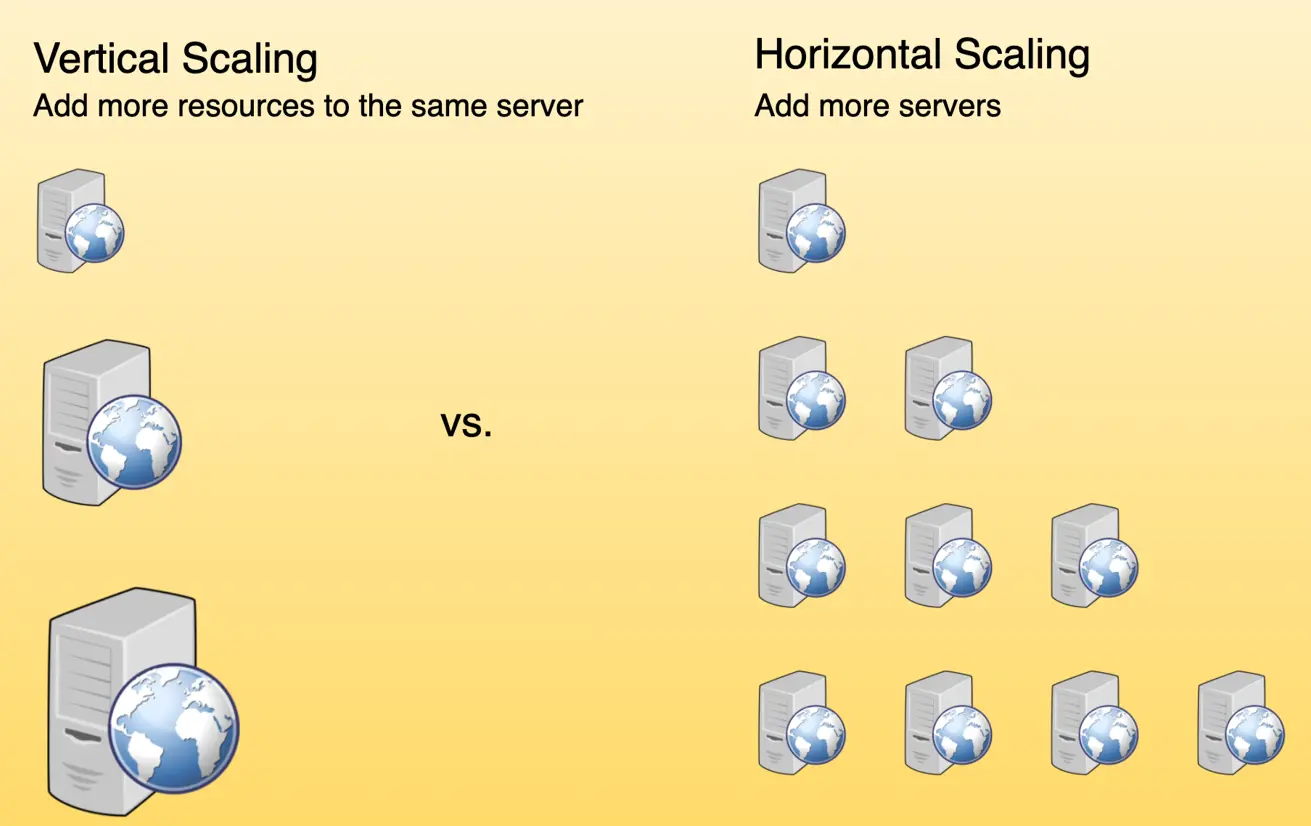
Scalability
Scalability refers to a system’s ability to handle increasing workloads. In system design, there are two primary types of scaling: horizontal and vertical. Horizontal scaling involves adding more machines to distribute the load across multiple servers, while vertical scaling typically involves upgrading the hardware of a single machine.SHOW CONTENTS
Availability
In system design, availability refers to the ability of a system to remain operational even in the face of faulures or high demand. Factors that affect availability include redundency, failover mechanisms, and load balancing. Redundency involves duplicating critical components to ensure that if one fails, another can take over. Failover mechanisms refer to the ability to quickly switch to a backup system during failure. Load balancing distributes requests across multiple servers to prevent any single point from becoming overwhelmed. In distributed systems, there is often a trade-off between availability and consistency. The three common types of consistency models are strong, weak, and eventual consistency. The strong consistency model ensure that all replicas have the same data at all times, which can reduce availability and performance. The weak consistency model allows for temporary inconsistencies between replicas, offering improved availability and performance. The eventual consistency model guarantees that all replicas will eventually converge to the same data, balancing consistency and availability over time.SHOW CONTENTS
Monitoring
Monitoring in distributed systems is crucial for identifying issues and ensuring the overall health of the system. It typically involves four key components: metrics collection, distributed tracing, logging, and anomaly detection. Metrics collection involves gathering and analyzing key performance indicators such as latency, throughput, error rates, and resource utilization. This helps identify performance bottlenecks, potential issues, and areas for optimization. Common tools for metrics collection inculde Prometheus, Graphite, and InfluxDB. Distributed tracing is a technique for tracking and analyzing requests as they pass through various services, helping identify issues within specific services. Common tools for distributed tracing include Zipkin. Logging refers to the collection, centralization, and analysis of logs from all services in a distributed system. It provides valuable insights into system behavior, aiding in debugging and troubleshooting. Tools like the ELK Stack (Elasticsearch, Logstash, Kibana) are used for logging. Anomaly detection involves monitoring for unusual behaviors or patterns and notifying the appropriate team when such events occur. Tools like Grafana can be used for anomaly detection in distributed systems.SHOW CONTENTS
Caching
Introduction to Caching
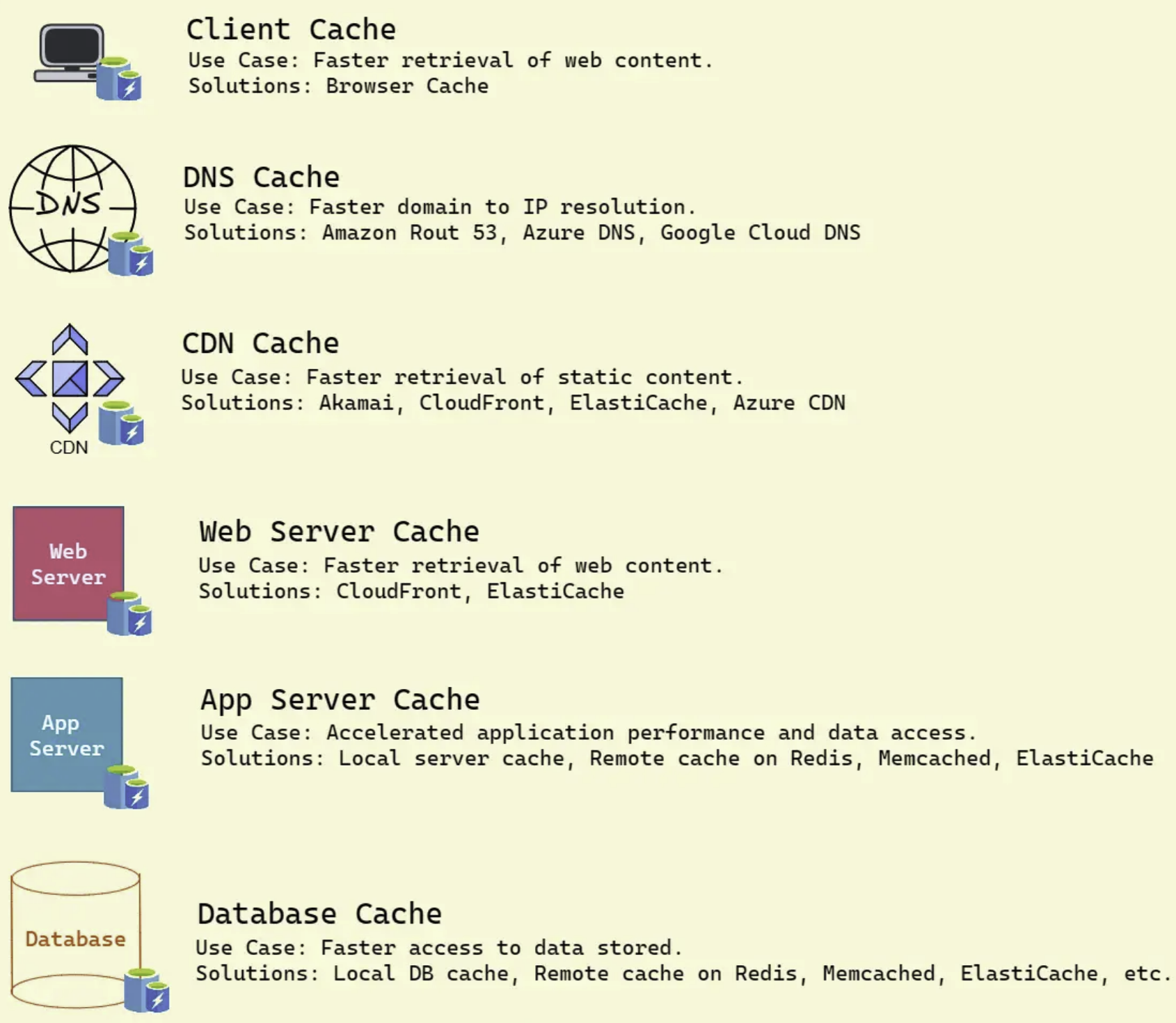
In system design, caching is a high-speed storage layer positioned between the application and the original data source, such as a database or a remote web service. The primary goal of caching is to minimize access to the original data source, thereby improving application performance. Caching can be implemented in various forms, including in-memory caching, disk caching, database caching, and CDN caching: Here are some key caching terms: Here are some of the most common types of caching:SHOW CONTENTS
Caching Replacement Policies
When caching data becomes outdated, it should be removed. Therefore, specifying a cache replacement policy is crucial when implementing caching. Common cache replacement policies include: LRU (Least Recently Used), LFU (Least Frequently Used), FIFO (First In, First Out), and Random Replacement.SHOW CONTENTS
Cache Invalidation
Cache Invalidation is the process of marking data in the cache as stale or directly removing it from the cache, ensuring that the cache doesn’t serve outdated or incorrect data. Common cache invalidation schemes include write-through cache, write-around cache, write-back cache, and write-behind cache. Here are some of the most commonly used cache invalidation methods:SHOW CONTENTS
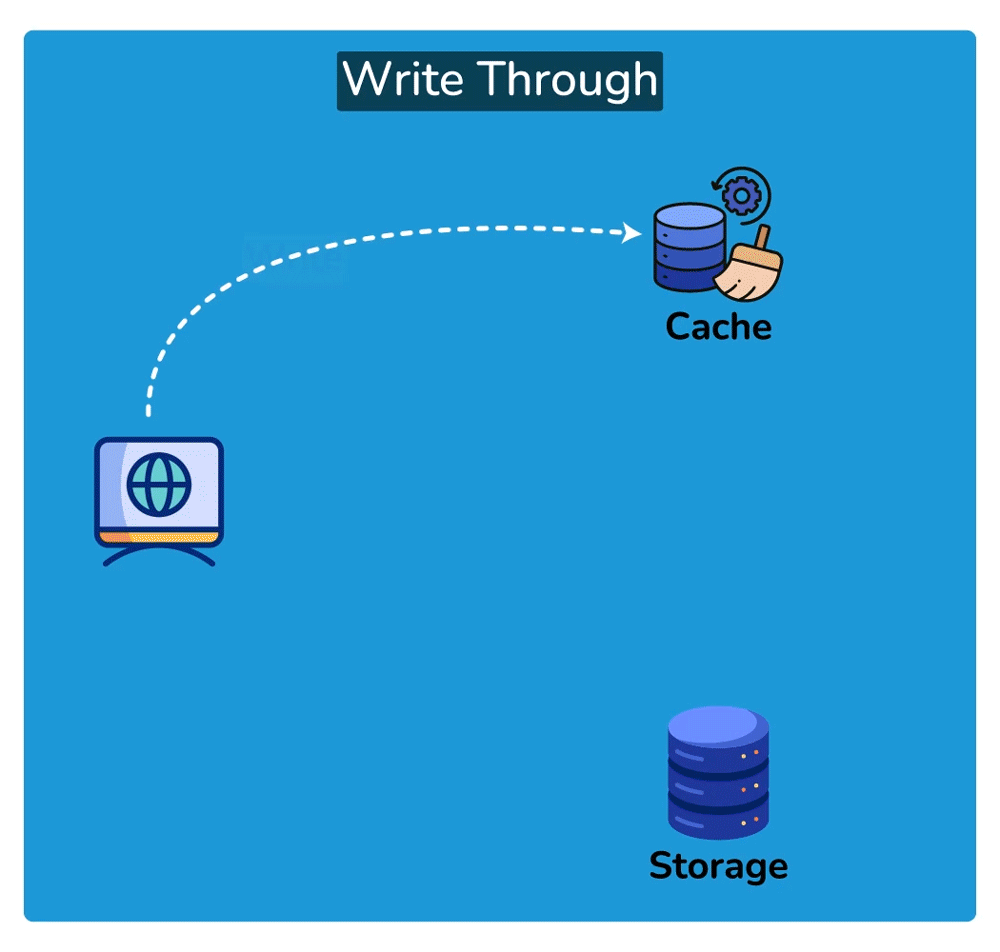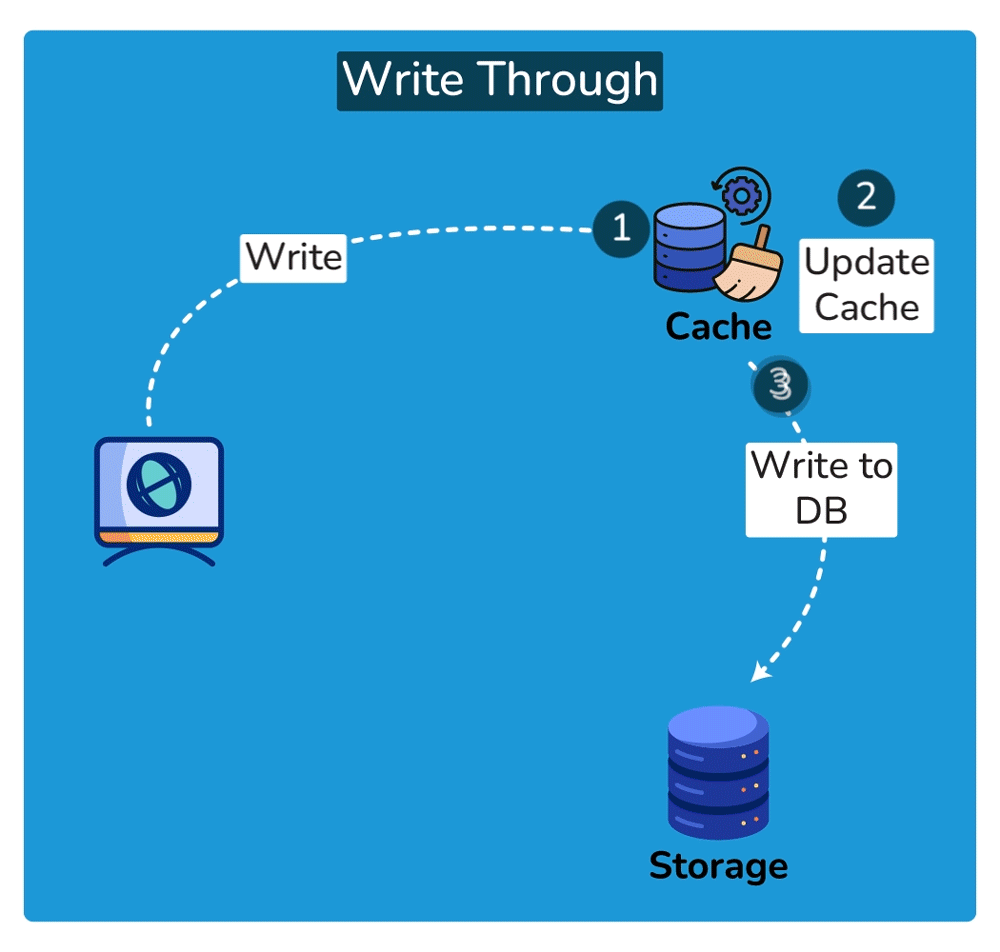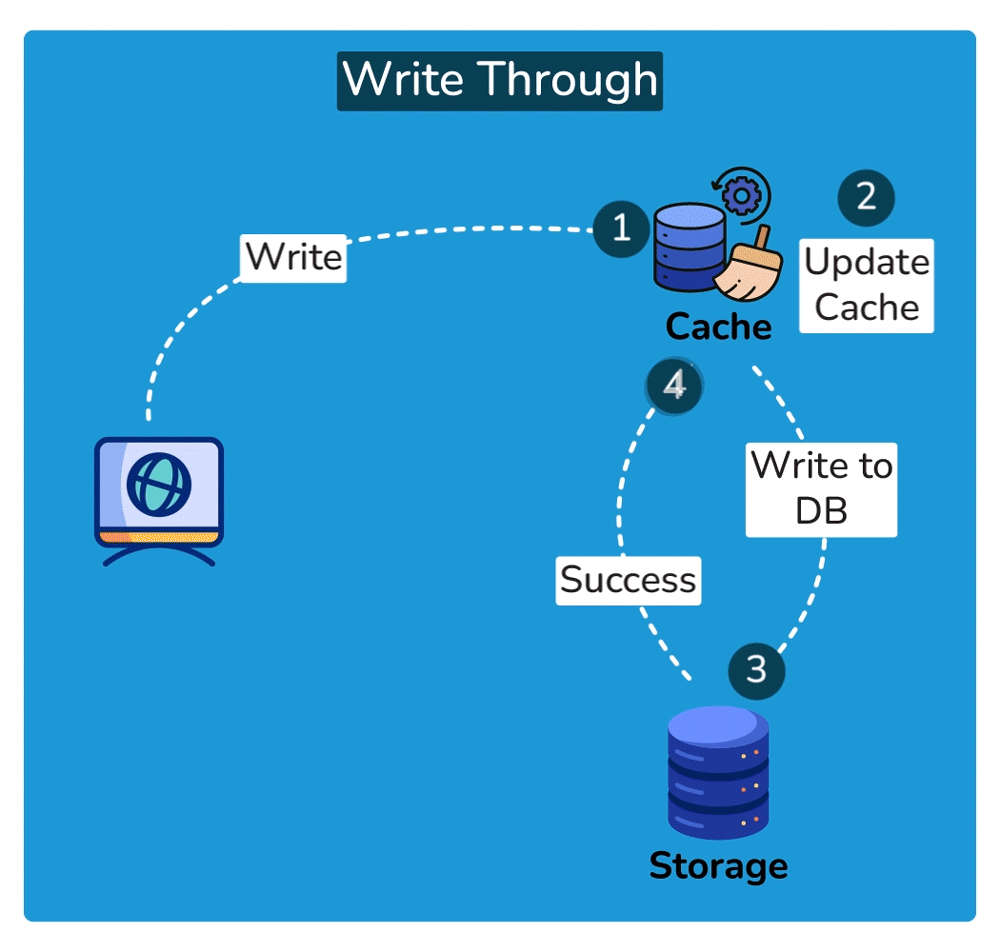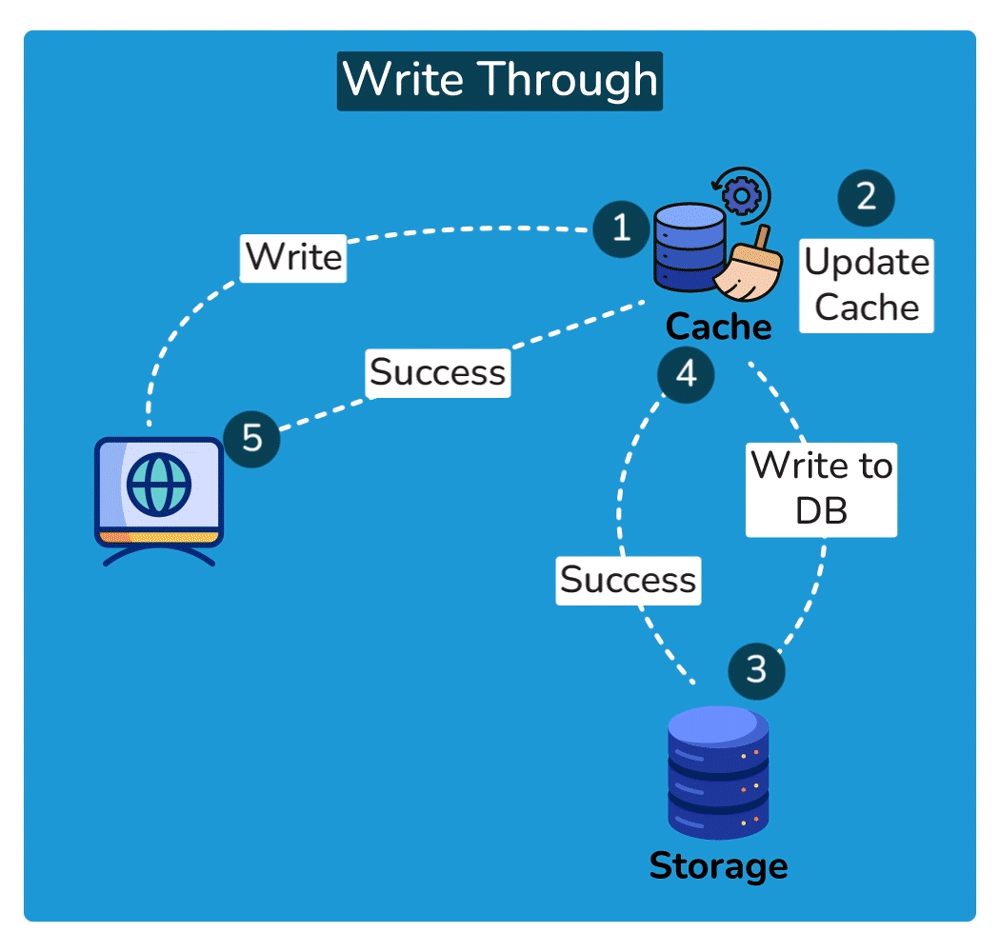
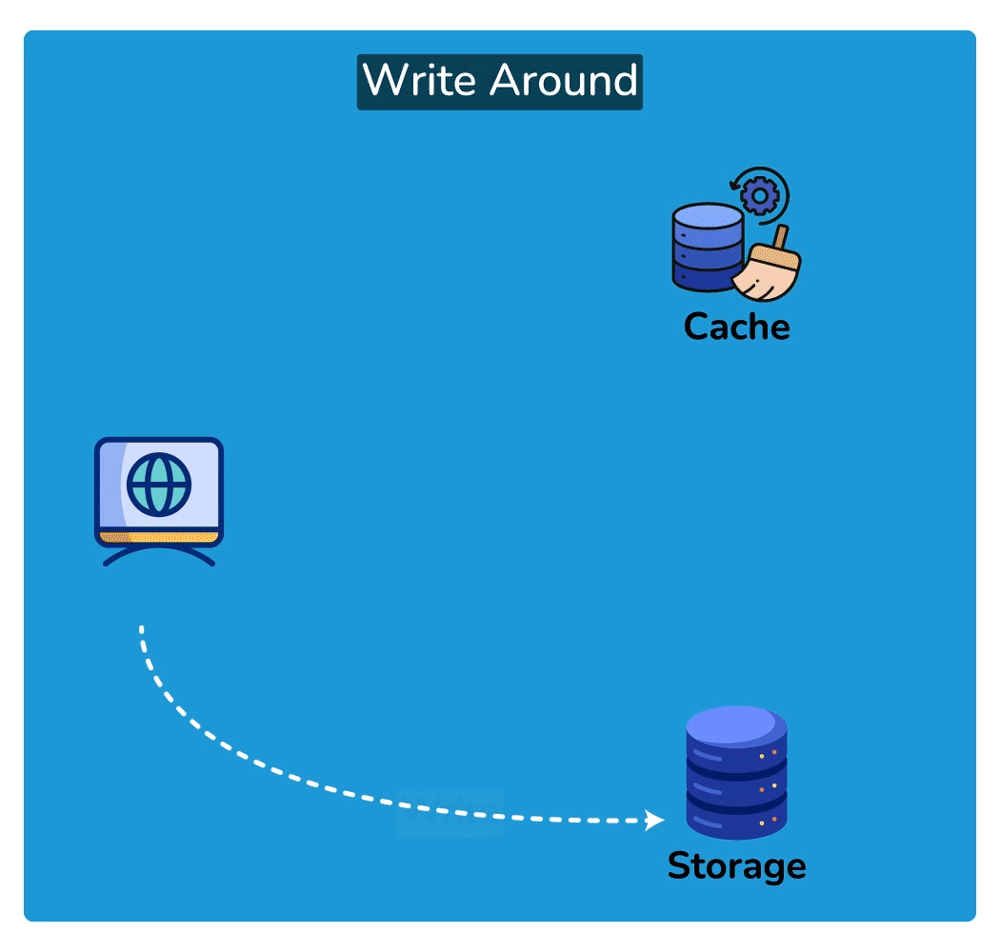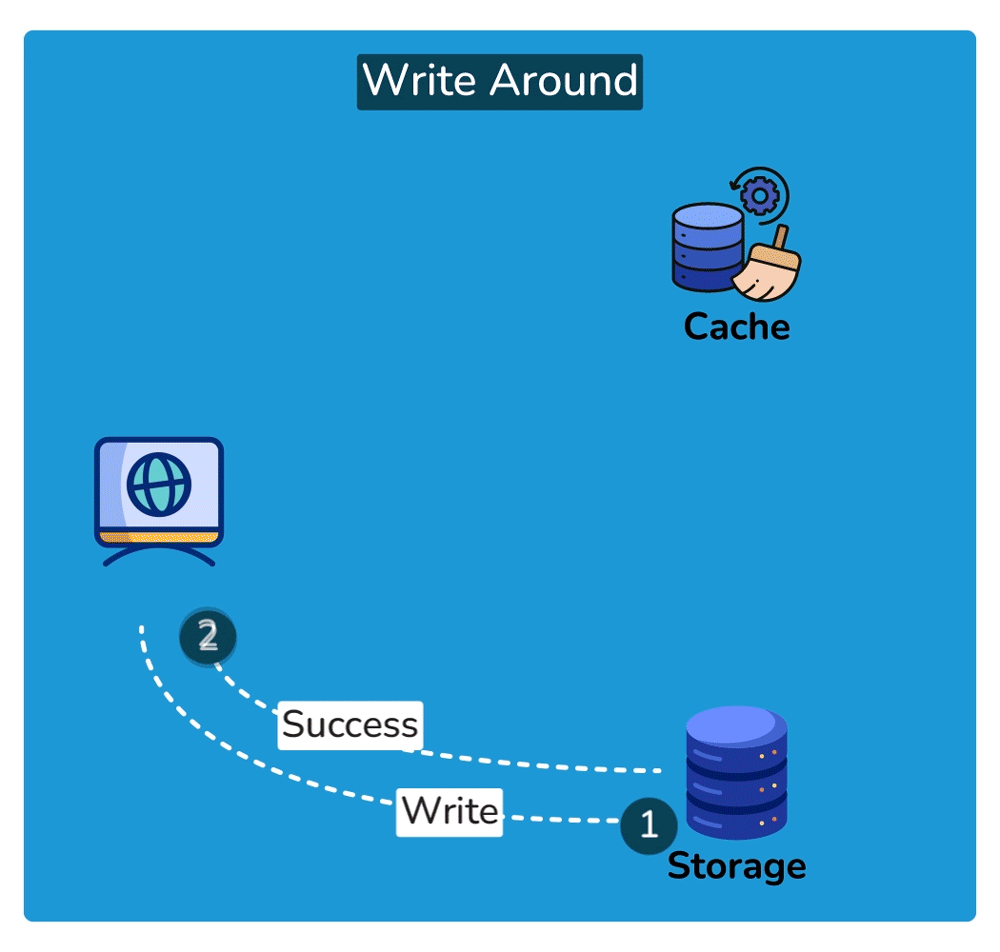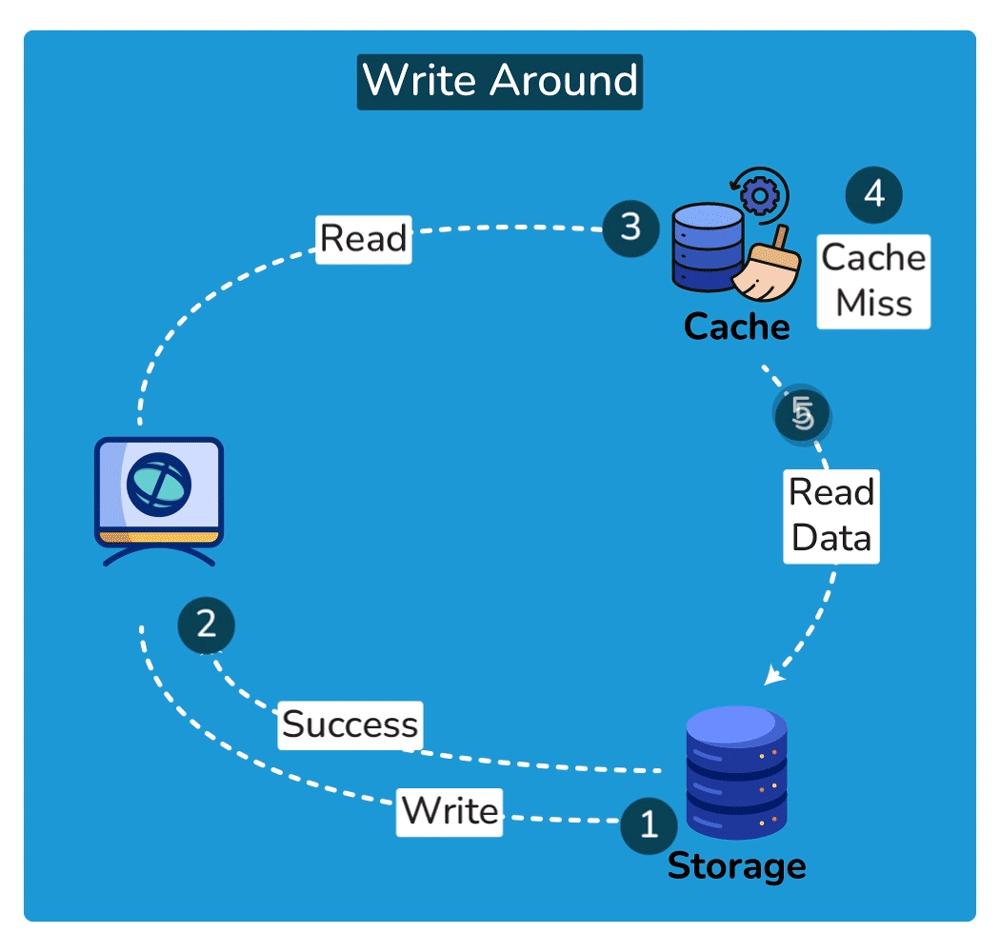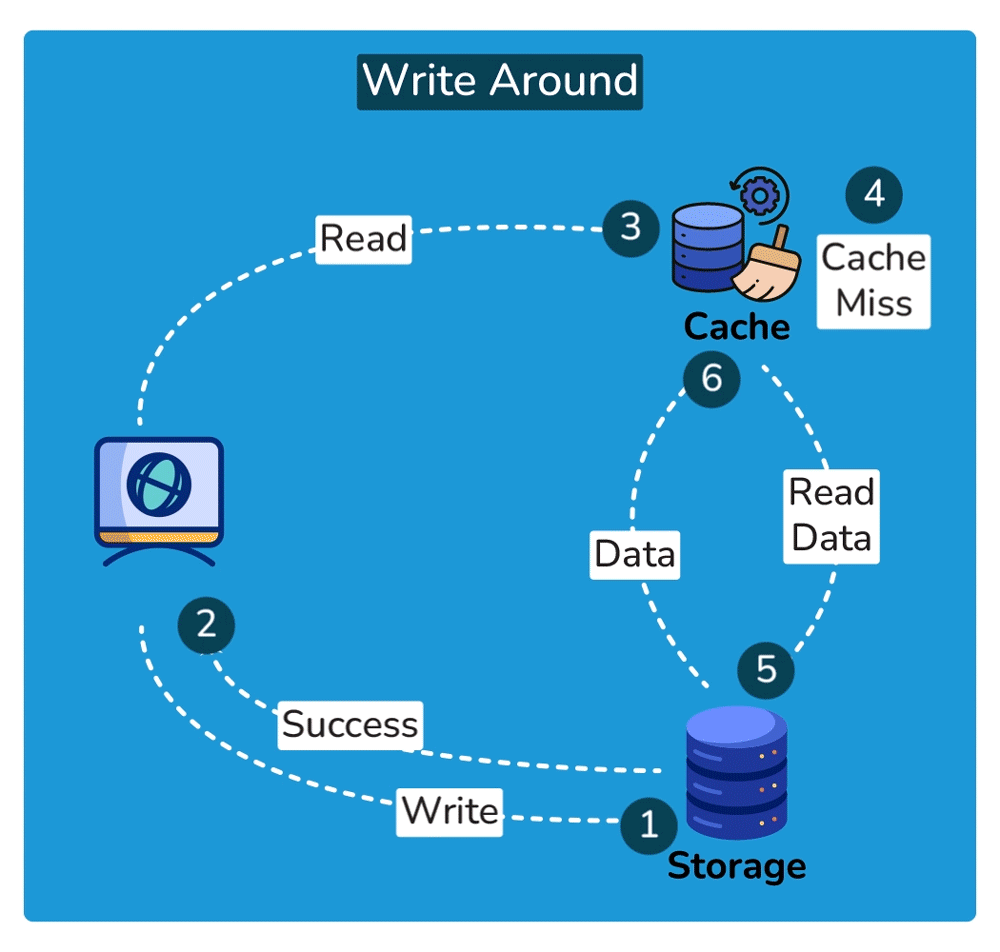
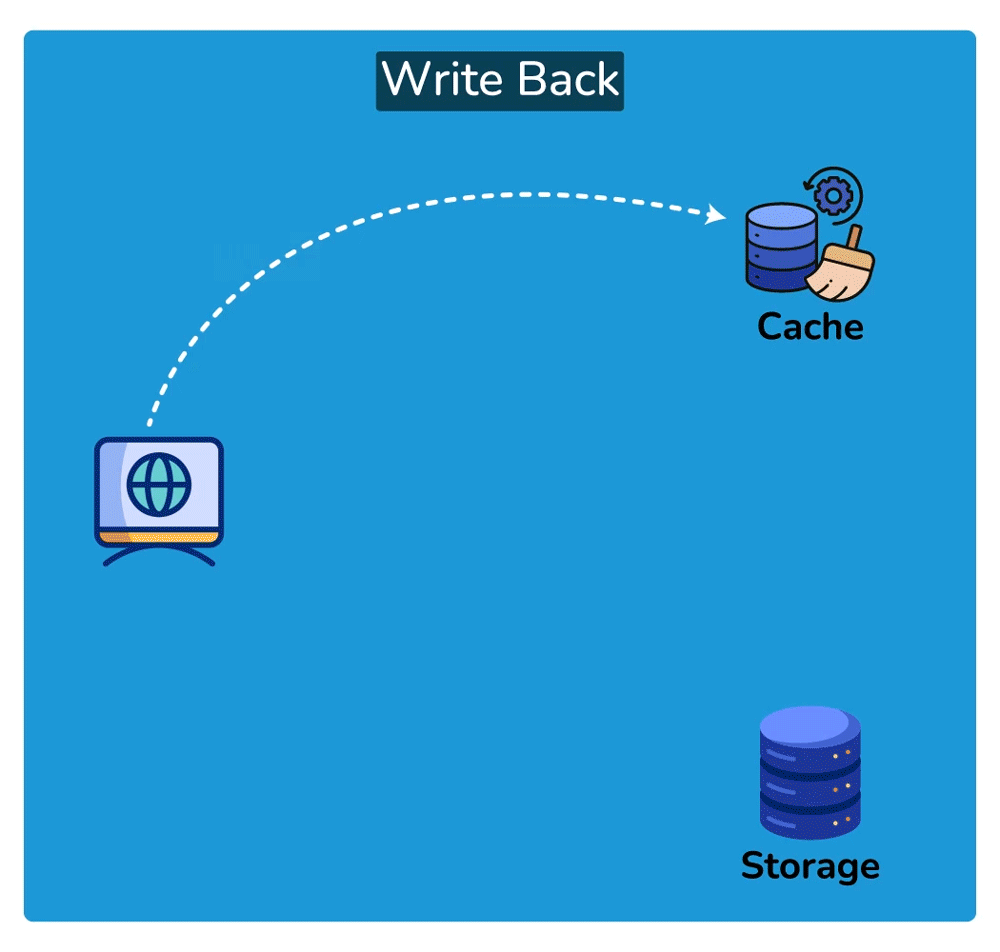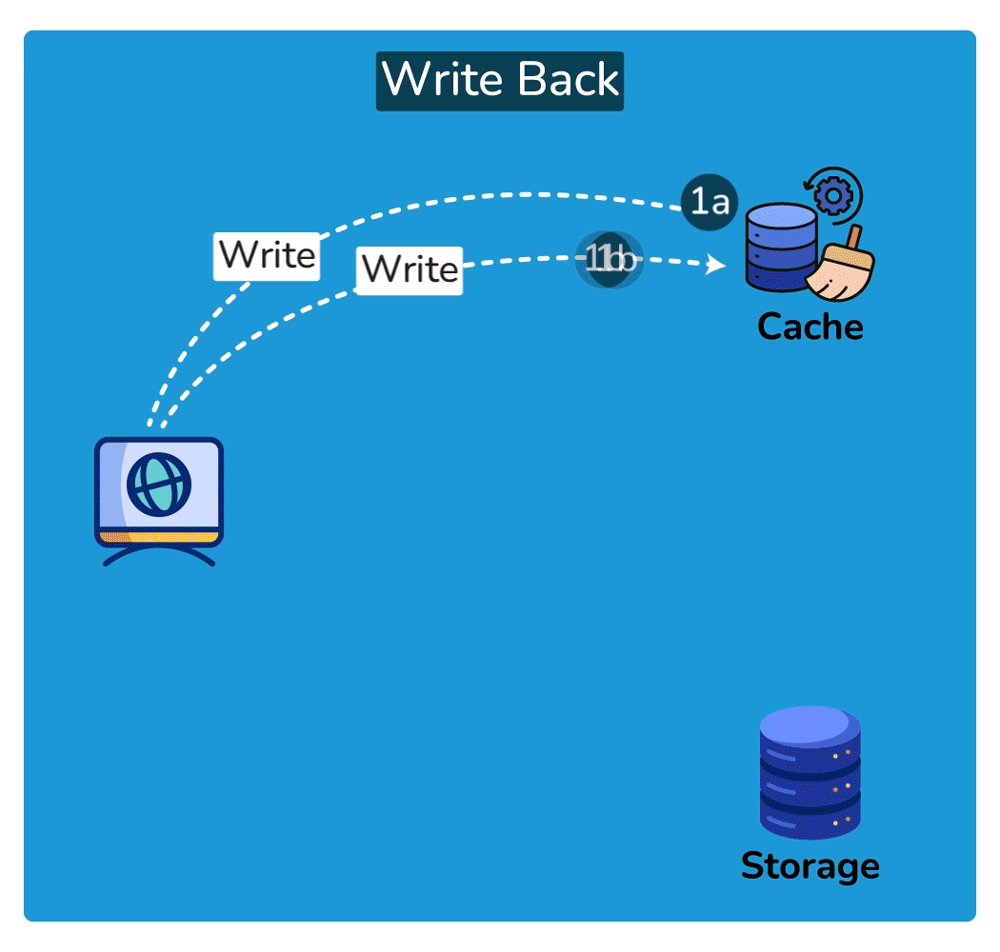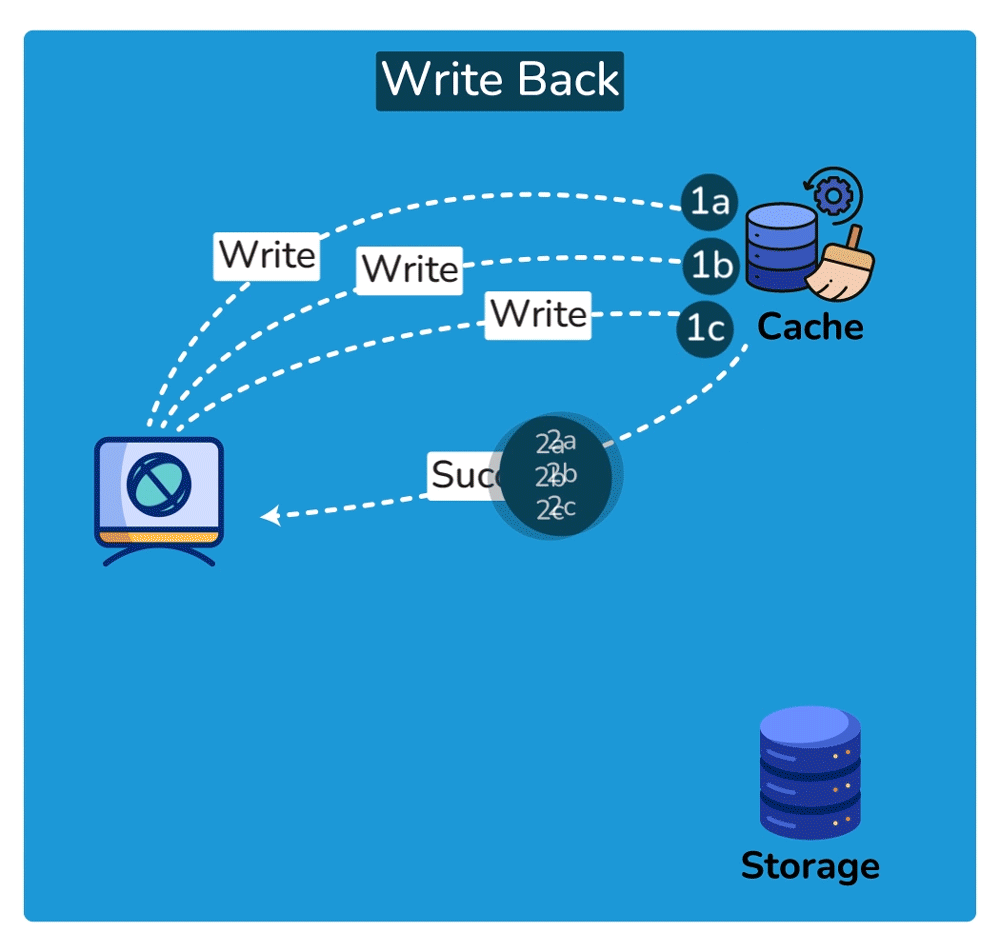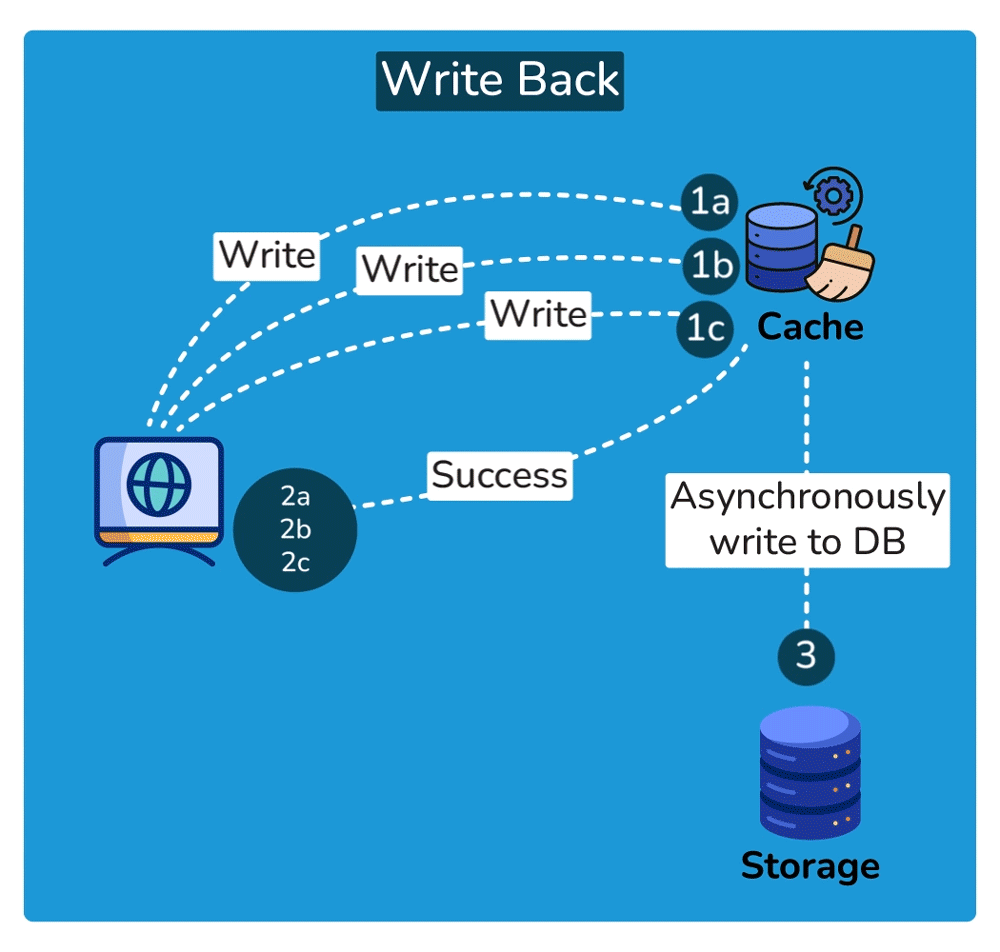
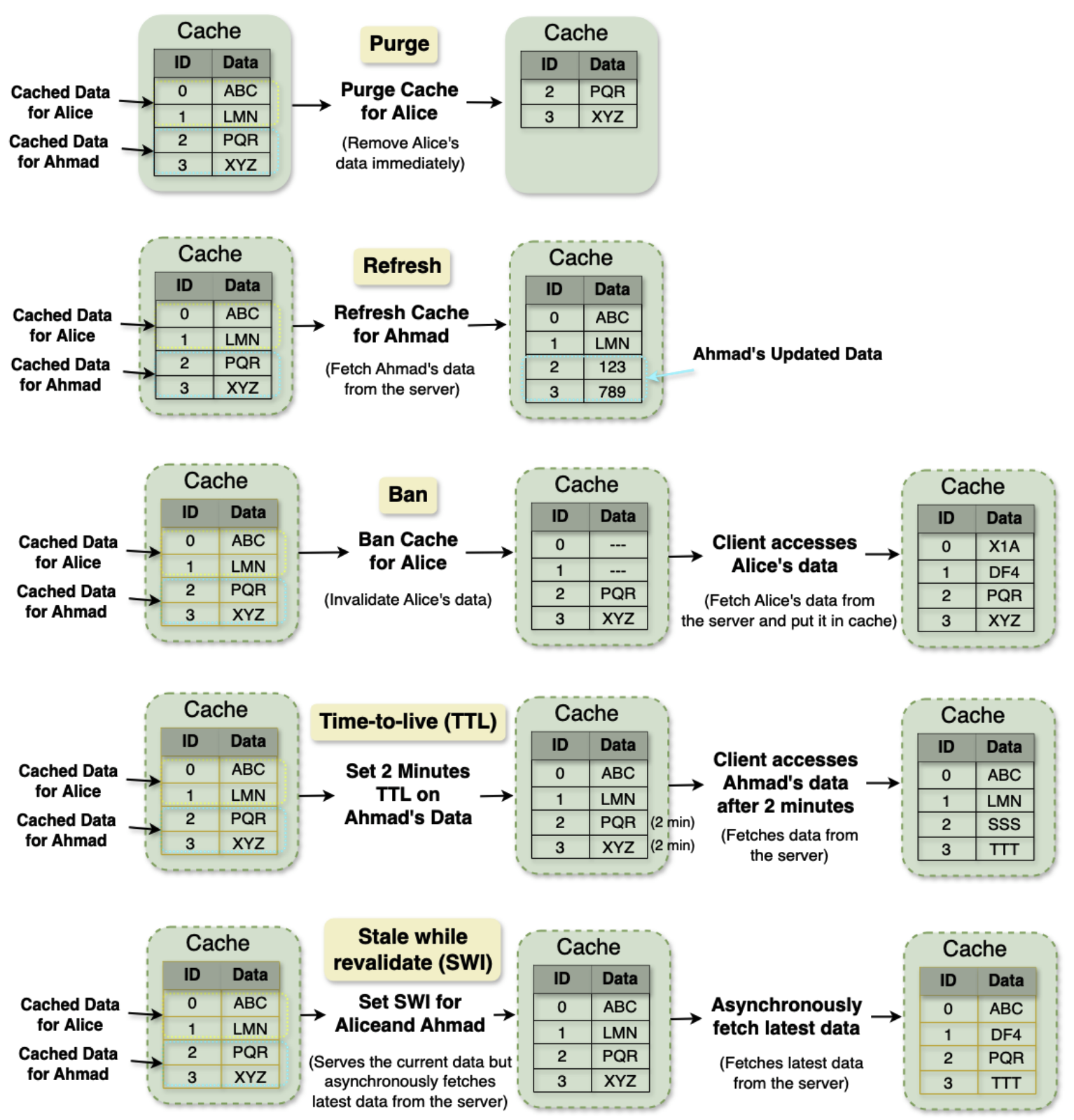
Cache Read Strategies
Cache read strategies define how the cache behaves when a cache miss occurs. The most common cache read strategies are read-through and read-aside.SHOW CONTENTS
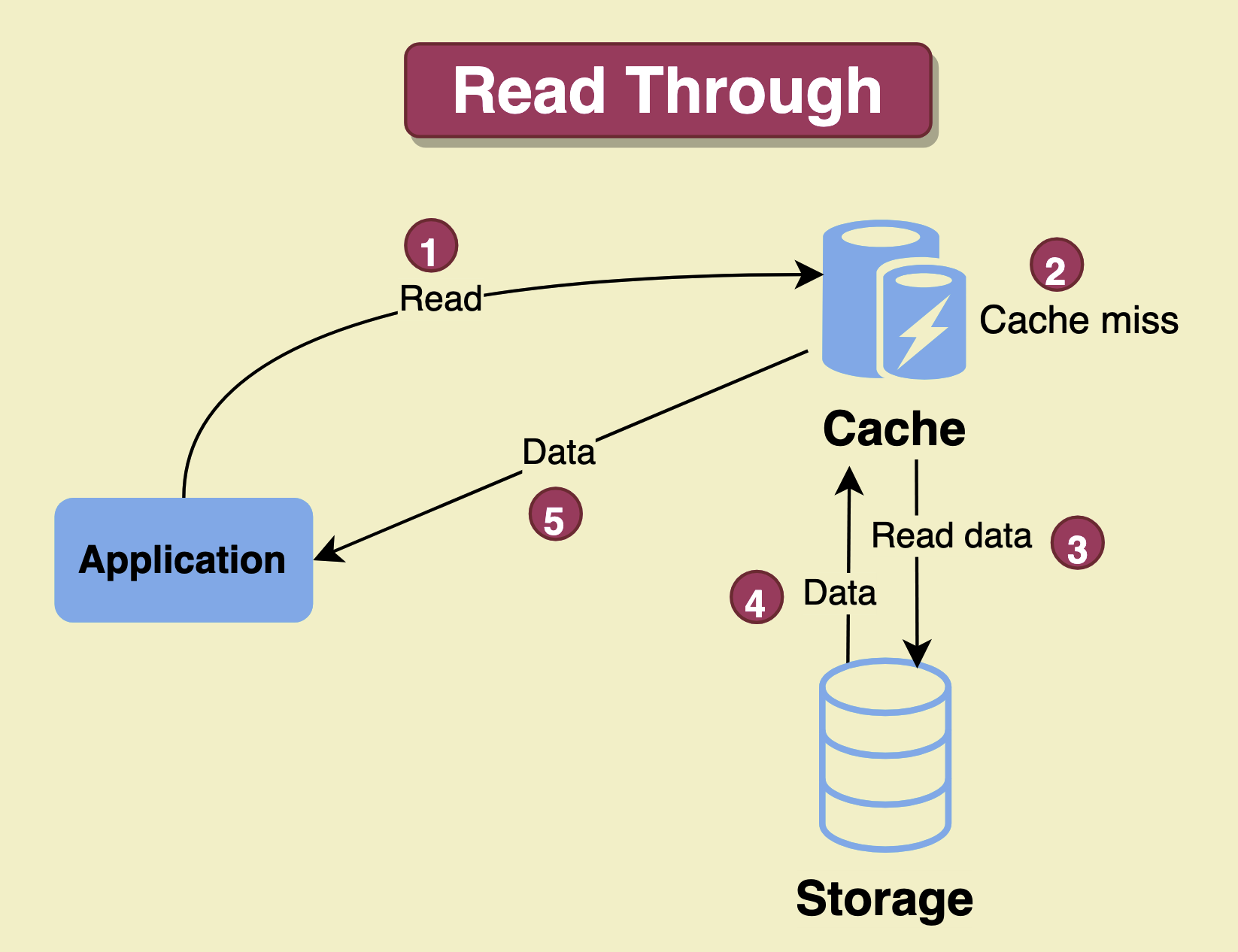
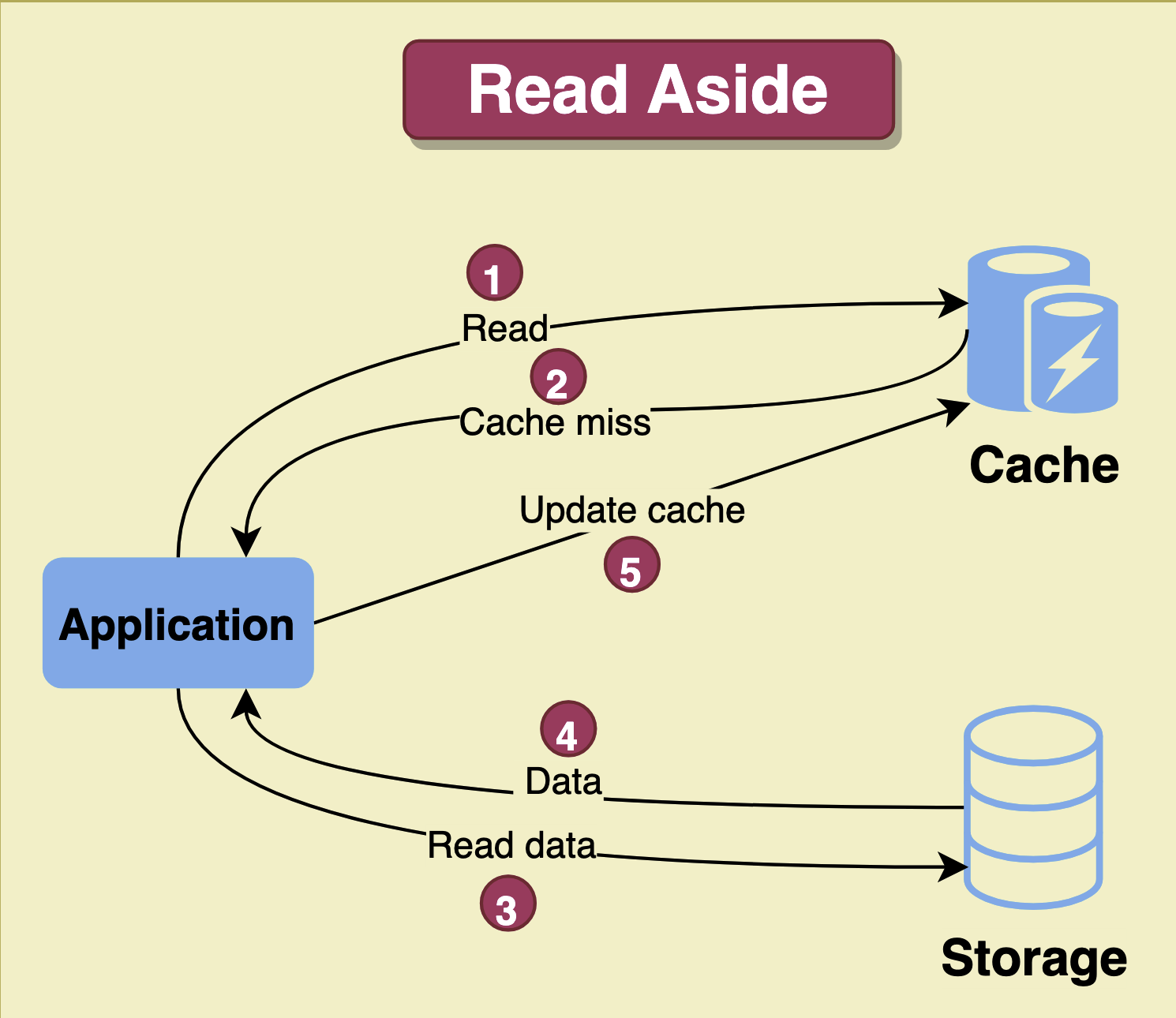
Cache Coherence and Cache Consistence
Cache coherence refers to the consistency of data stored in multiple caches that are part of the same system, particularly in multi-core systems. In a distributed system, each cache may store a local copy of shared data. When one cache modifies its copy, all other caches holding a copy of that data must be updated or invalidated to maintain consistency. The most common protocols for achieving cache coherence are write-invalidate and write-update. Cache consistency focuses on maintaining the consistency of data between the cache and the original data source. Cache consistency models define the rules governing how data is updated and accessed in a distributed system with multiple caches. These models vary in terms of their strictness, and include strict consistency, sequential consistency, casual consistency, and eventual consistency.SHOW CONTENTS
Caching Challenges
The main cache-related issues include Thundering Herd, Cache Penetration, Cache Stampede, and Cache Pollution. Thundering Herd: This problem arises when a popular piece of data expires, leading to a sundden surge of requests to the original server, resulting in performance degradation. Solutions include staggered expiration times, cache locking, or background updates before expiration. Cache Penetration: This occurs when multiple requests for non-existent data bypass the cache, querying the original data store directly. Solutions include negative caching (caching “not found” responses) or using a Bloom Filter to check the existence of data before querying the cache. Cache Stampede: This happens when multiple requests for the same data arrive after cache expires, causing a heavy load on the original data source. Solutions typically involve request coalescing (letting on request fetch the data while others wait) or implementing a read-through cache, where the cache itself fetches missing data. Cache Pollution: This occurs when less frequently accessed data displaces more frequently accessed data, reducing cache hit rates. To mitigate cache pollution, eviction policies such as LRU (Least Recently Used) or LFU (Least Frequently Used) can be implemented.SHOW CONTENTS

Data Partitioning
In system design, data partitioning is a technique used to break large datasets into smaller, more manageable units called partitions. Each partition is independent and contains a subset of the overall data. Common data partitioning methods include horizontal partitioning and vertical partitioning. Data sharding splits table horizontally, here are some common sharding techniques.SHOW CONTENTS
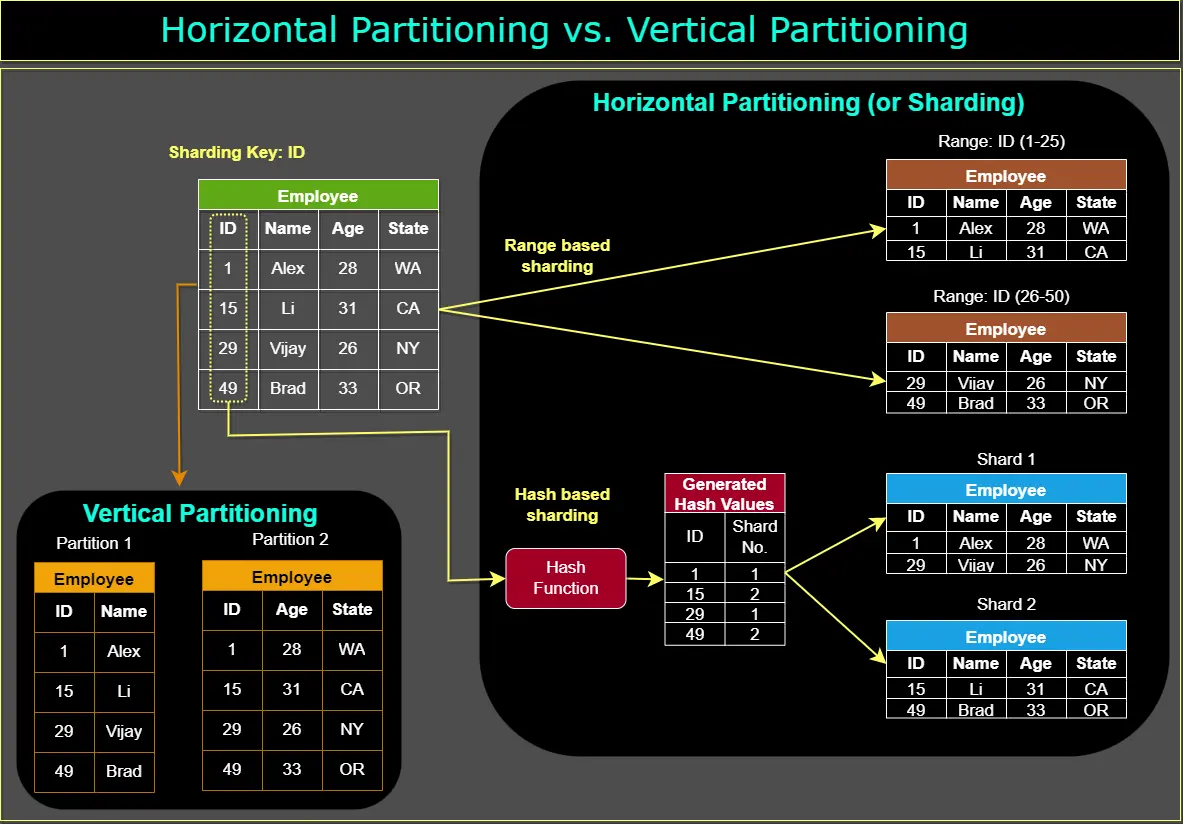
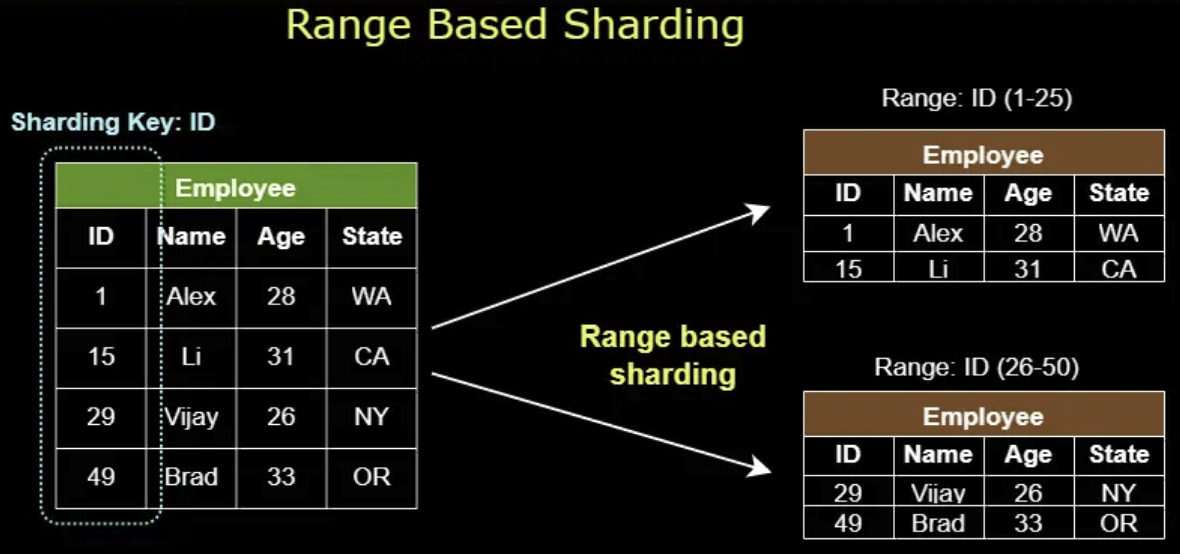
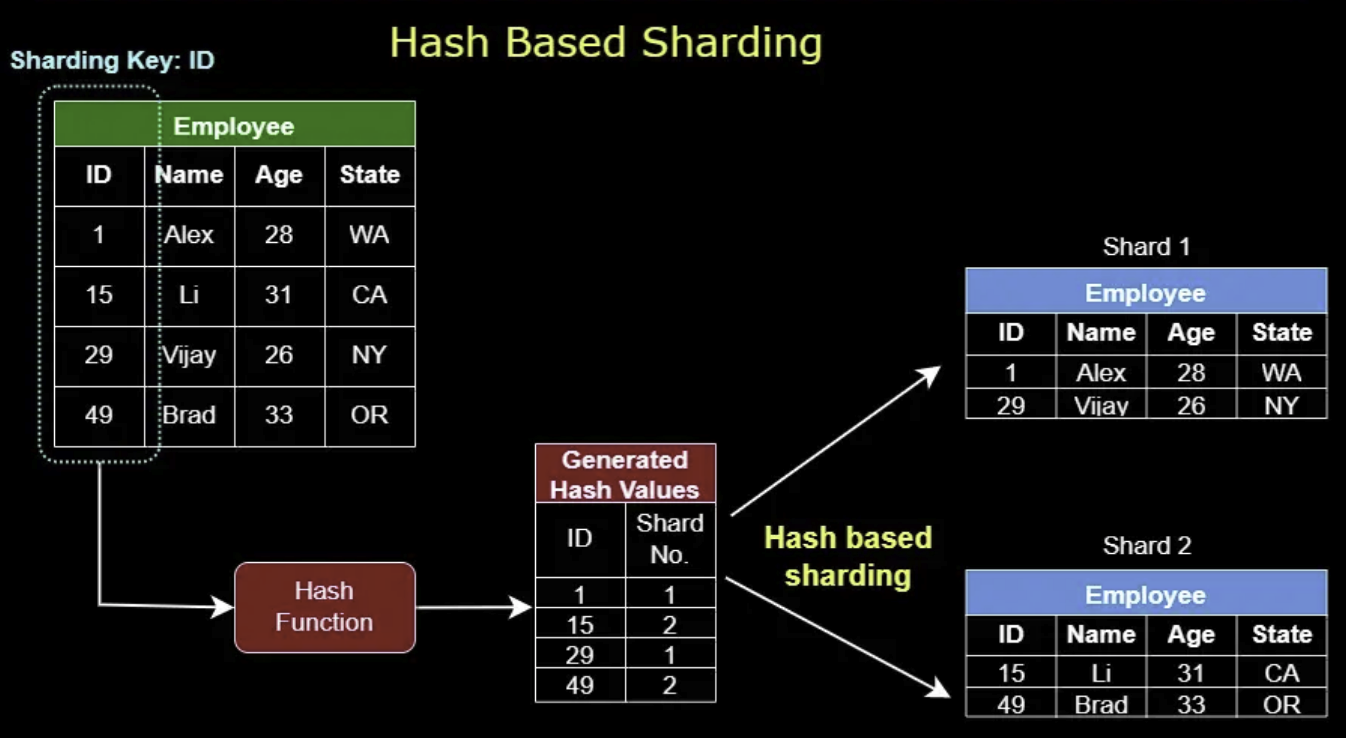
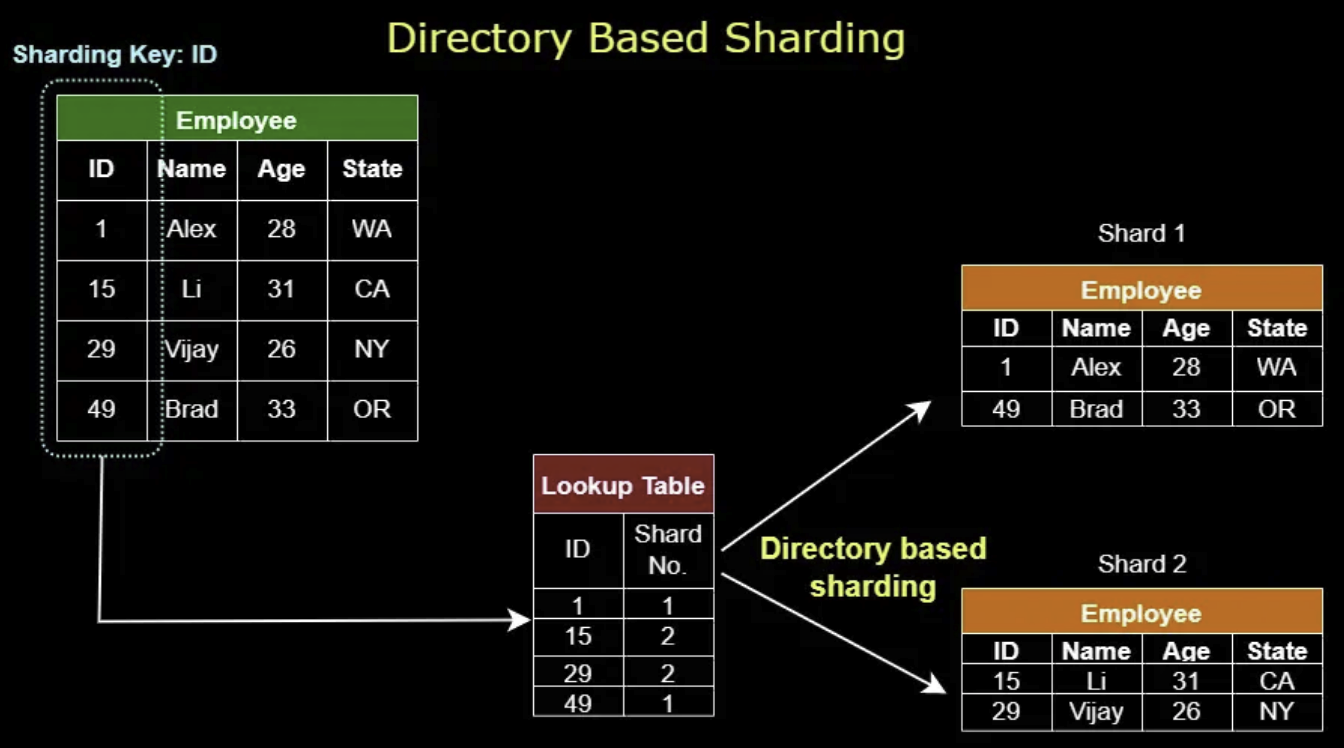

Proxy
A proxy is an intermediary server or software that sits between the client and the internet, typically used for tasks like filtering, caching, or security checks. Proxies can consolidate multiple client requests into a single request, a process known as collapsed forwarding. For instance, if multiple clients request the same resource, the proxy can cache the resource and serve it to those clients without having to forward the request to the origin server each time. There are two main types of proxies: forward proxy and reverse proxy. A forward proxy acts on behalf of the client, hiding its identity by forwarding requests from the client to the server. It is often used to mask the client’s IP address, bypass geo-restrictions, or cache content for faster access. A reverse proxy, on the other hand, acts on behalf of the server, intercepting incoming requests from clients and directing them to the appropriate backend server. This type of proxy is commonly used for load balancing, caching, and enhancing security by hiding the backend server details from clients.SHOW CONTENTS

Replication
SHOW CONTENTS
Replication Methods
SHOW CONTENTS
CAP Theorem
SHOW CONTENTS
Database Federation
SHOW CONTENTS
Security
SHOW CONTENTS
Distributed Messaging System
SHOW CONTENTS
Distributed File System
SHOW CONTENTS
Misc Concepts
Bloom Filters
SHOW CONTENTS
Long-Polling, WebSockets, and Server-Sent Events
SHOW CONTENTS
Quorum
SHOW CONTENTS
Heartbeat
SHOW CONTENTS
Leader and Follower
SHOW CONTENTS
Message Queues vs. Service Bus
SHOW CONTENTS
Stateful vs. Stateless Architecture
SHOW CONTENTS
Event-Driven vs. Polling Architecture
SHOW CONTENTS